How to Implement Sorting Algorithms in Python? It’s a question every coder wrestles with at some point. This isn’t just about memorizing code; it’s about understanding the *why* behind each algorithm – from the simplicity of bubble sort to the elegance of merge sort. We’ll dive deep into the practical implementation of several key algorithms, comparing their strengths and weaknesses so you can choose the right tool for the job. Get ready to level up your Python skills!
We’ll cover the fundamentals of sorting, explore common algorithms like bubble sort, insertion sort, selection sort, merge sort, quicksort, and heapsort, and analyze their time and space complexities. We’ll provide clear, concise code examples for each, along with step-by-step explanations to ensure you grasp the underlying logic. By the end, you’ll not only be able to implement these algorithms but also confidently choose the most efficient one for any given scenario. Plus, we’ll show you how to leverage Python’s built-in sorting functions for optimal performance.
Introduction to Sorting Algorithms in Python
Sorting algorithms are fundamental to computer science, forming the backbone of many applications. They dictate how we arrange data in a specific order, whether alphabetically, numerically, or based on any defined criteria. Efficient sorting is crucial for optimizing search, database management, and data analysis tasks. Imagine trying to find a specific name in an unsorted phone book – a nightmare! Sorting algorithms provide the solution, making data retrieval significantly faster and more efficient.
Common Sorting Algorithms
Several different sorting algorithms exist, each with its own strengths and weaknesses. The choice of algorithm depends heavily on factors like the size of the data set, whether the data is nearly sorted, and memory constraints. We’ll explore some of the most common algorithms: Bubble Sort, Insertion Sort, Selection Sort, Merge Sort, Quicksort, and Heapsort.
Algorithm Comparisons
Understanding the time and space complexity of these algorithms is key to choosing the right one for a given task. Time complexity describes how the runtime of the algorithm scales with the input size (often denoted as ‘n’), while space complexity describes the amount of extra memory the algorithm requires. We generally express these complexities using Big O notation.
| Algorithm | Time Complexity (Best) | Time Complexity (Average) | Time Complexity (Worst) | Space Complexity |
|---|---|---|---|---|
| Bubble Sort | O(n) | O(n2) | O(n2) | O(1) |
| Insertion Sort | O(n) | O(n2) | O(n2) | O(1) |
| Selection Sort | O(n2) | O(n2) | O(n2) | O(1) |
| Merge Sort | O(n log n) | O(n log n) | O(n log n) | O(n) |
| Quicksort | O(n log n) | O(n log n) | O(n2) | O(log n) |
| Heapsort | O(n log n) | O(n log n) | O(n log n) | O(1) |
This table shows that algorithms like Merge Sort and Heapsort consistently offer O(n log n) time complexity, making them suitable for larger datasets. Bubble Sort, Insertion Sort, and Selection Sort, while simpler to understand, become significantly slower as the data size increases. Quicksort, while offering excellent average-case performance, can degrade to O(n2) in worst-case scenarios (e.g., already sorted data). The space complexity indicates the memory overhead; algorithms with O(1) space complexity are generally preferred for memory-constrained environments.
Bubble Sort Implementation
Bubble Sort is one of the simplest sorting algorithms, making it a great starting point for understanding how sorting works. Its straightforward nature, however, comes at the cost of efficiency; it’s not suitable for large datasets due to its slow performance. Let’s dive into how it functions and how to implement it in Python.
Bubble Sort works by repeatedly stepping through the list, comparing adjacent elements and swapping them if they are in the wrong order. The pass through the list is repeated until no swaps are needed, which indicates that the list is sorted. Think of it like bubbles rising to the surface – the largest elements “bubble” up to their correct positions.
Bubble Sort Algorithm Steps
The process of sorting a list using the Bubble Sort algorithm can be broken down into these key steps:
- Compare the first two elements. If the first element is greater than the second, swap them.
- Compare the second and third elements. If the second element is greater than the third, swap them.
- Repeat this process for all adjacent pairs of elements in the list.
- After the first pass, the largest element will be in its correct position at the end of the list.
- Repeat steps 1-4 for the remaining unsorted portion of the list (excluding the last element, which is already sorted).
- Continue this process until no swaps are made in a pass, indicating that the list is fully sorted.
Python Code Implementation of Bubble Sort
Here’s a Python function that implements the Bubble Sort algorithm:
def bubble_sort(list_):
n = len(list_)
for i in range(n-1):
for j in range(n-i-1):
if list_[j] > list_[j+1]:
list_[j], list_[j+1] = list_[j+1], list_[j]
return list_
Bubble Sort Example
Let’s trace the execution of the Bubble Sort algorithm on a sample array: [5, 1, 4, 2, 8]
Pass 1:
- Compare 5 and 1: Swap (1, 5, 4, 2, 8)
- Compare 5 and 4: Swap (1, 4, 5, 2, 8)
- Compare 5 and 2: Swap (1, 4, 2, 5, 8)
- Compare 5 and 8: No swap (1, 4, 2, 5, 8)
Pass 2:
Mastering Python’s sorting algorithms like merge sort or quicksort is key to efficient data handling, but your code’s efficiency is useless if a cyberattack wipes out your project. That’s why securing your digital assets is crucial; check out this guide on How to Protect Your Digital Assets with Cyber Insurance to safeguard your hard work. After all, what good is perfectly sorted data if it’s gone forever?
- Compare 1 and 4: No swap (1, 4, 2, 5, 8)
- Compare 4 and 2: Swap (1, 2, 4, 5, 8)
- Compare 4 and 5: No swap (1, 2, 4, 5, 8)
Pass 3:
- Compare 1 and 2: No swap (1, 2, 4, 5, 8)
- Compare 2 and 4: No swap (1, 2, 4, 5, 8)
Pass 4: No swaps are needed, indicating the list is sorted: [1, 2, 4, 5, 8]
Insertion Sort Implementation
Insertion sort is another fundamental sorting algorithm, often praised for its simplicity and efficiency on small datasets or nearly sorted data. Unlike bubble sort, which repeatedly steps through the list, insertion sort builds a sorted array one element at a time. Think of it like organizing a hand of playing cards – you pick up one card at a time and insert it into its correct position within the already sorted cards in your hand.
Insertion sort works by iterating through the array and, for each element, comparing it to the elements before it and shifting those elements to the right until it finds the correct position to insert the current element. This process maintains a sorted subarray at the beginning of the array, gradually expanding until the entire array is sorted.
Algorithm Steps
The process of insertion sort can be broken down into these key steps. Understanding these steps will make the Python code much clearer.
- Start with the second element of the array (index 1).
- Compare the current element with the elements before it (in the sorted subarray).
- If the current element is smaller than the element before it, shift the preceding element one position to the right.
- Repeat step 3 until the current element is in its correct sorted position within the sorted subarray, or you reach the beginning of the array.
- Move to the next element and repeat steps 2-4 until the end of the array is reached.
Python Code Implementation
Here’s a Python function that implements the insertion sort algorithm:
def insertion_sort(arr):
for i in range(1, len(arr)):
key = arr[i]
j = i - 1
while j >= 0 and key < arr[j]:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key
return arr
#Example usage
my_list = [12, 11, 13, 5, 6]
sorted_list = insertion_sort(my_list)
print("Sorted array is:", sorted_list)
This code iterates through the array, taking each element as a 'key'. The inner `while` loop shifts larger elements to the right to make space for the 'key' in its correct sorted position. The final `arr[j + 1] = key` line inserts the 'key' into its rightful place. The example shows how to use the function and demonstrates its output. Note that the function modifies the list in place; it doesn't create a new sorted list.
Time and Space Complexity
The time complexity of insertion sort is O(n^2) in the worst and average cases, but it achieves O(n) in the best case (when the array is already sorted). This makes it a good choice for small datasets or nearly sorted data, where its simplicity outweighs the potential performance penalty of a quadratic time complexity. The space complexity is O(1), making it an in-place sorting algorithm. This means it sorts the array without needing significant extra memory, unlike some other algorithms that require creating temporary arrays.
Selection Sort Implementation

Source: cloudfront.net
Selection sort is another fundamental sorting algorithm, often taught alongside bubble sort and insertion sort. While it's not the most efficient algorithm for large datasets, understanding its mechanics provides valuable insight into sorting principles. It's known for its simplicity and predictable memory usage.
Selection sort works by repeatedly finding the minimum element from the unsorted part of the array and placing it at the beginning. The algorithm maintains two subarrays: one sorted and one unsorted. In each iteration, the minimum element from the unsorted subarray is picked and moved to the sorted subarray.
Selection Sort Algorithm Logic
The core of selection sort lies in its iterative approach. The algorithm iterates through the unsorted portion of the array, identifying the smallest element within that portion. Once identified, this minimum element is swapped with the element at the beginning of the unsorted portion. This process is repeated until the entire array is sorted. Consider this step-by-step breakdown:
1. Find the minimum: The algorithm scans the unsorted part of the array to locate the minimum element.
2. Swap: The minimum element is then swapped with the first element of the unsorted portion.
3. Iteration: The sorted portion of the array grows by one element, and the process repeats for the remaining unsorted portion.
Python Implementation of Selection Sort
Here's a Python function implementing the selection sort algorithm:
```python
def selection_sort(arr):
n = len(arr)
for i in range(n):
min_idx = i
for j in range(i+1, n):
if arr[j] < arr[min_idx]:
min_idx = j
arr[i], arr[min_idx] = arr[min_idx], arr[i] # Swap the found minimum element with the first element
return arr
```
This function iterates through the array, finds the minimum element in each pass, and swaps it to its correct position.
Selection Sort vs. Bubble Sort: A Performance Comparison
Let's compare the performance of selection sort and bubble sort using a sample array: `[64, 25, 12, 22, 11]`.
Bubble Sort: Bubble sort repeatedly steps through the list, compares adjacent elements and swaps them if they are in the wrong order. The pass through the list is repeated until the list is sorted. This process involves multiple comparisons and swaps for each element.
Selection Sort: Selection sort finds the minimum element in each pass and swaps it with the element at the beginning of the unsorted portion. It performs fewer swaps than bubble sort, but the number of comparisons remains relatively similar.
For the array `[64, 25, 12, 22, 11]`, bubble sort would require more iterations and swaps than selection sort to achieve a fully sorted state. While the exact number of comparisons and swaps depends on the initial order of elements, selection sort generally performs fewer swaps, leading to potentially better performance in scenarios with many already-sorted elements or when swap operations are computationally expensive. However, both algorithms have a time complexity of O(n^2) in the worst and average cases, meaning their performance degrades significantly as the input size increases.
Merge Sort Implementation

Source: realpython.com
Merge sort is a powerful sorting algorithm that elegantly tackles the problem of sorting large datasets. Unlike the simpler algorithms we've seen so far, merge sort employs a strategy known as "divide and conquer," breaking down the problem into smaller, more manageable subproblems, solving them recursively, and then combining the solutions to get the final sorted result. This approach makes it significantly more efficient for larger input sizes.
Merge sort's efficiency stems from its logarithmic time complexity, making it a preferred choice for many applications where performance is crucial. Let's delve into how it works and its Python implementation.
Divide and Conquer Approach in Merge Sort
Merge sort follows a three-step recursive process: Divide, Conquer, and Combine. First, the unsorted list is divided into smaller sublists until each sublist contains only one element (a single element is inherently sorted). This is the "Divide" step. Then, the "Conquer" step involves recursively sorting these single-element sublists (which are already sorted). Finally, the "Combine" step merges the sorted sublists to produce larger sorted sublists until a single, completely sorted list is obtained. This recursive merging is the heart of the algorithm's efficiency.
Python Implementation of Merge Sort
Here's a Python implementation of the merge sort algorithm, including the crucial `merge` function:
```python
def merge_sort(data):
if len(data) > 1:
mid = len(data) // 2
left_half = data[:mid]
right_half = data[mid:]
merge_sort(left_half)
merge_sort(right_half)
i = j = k = 0
while i < len(left_half) and j < len(right_half): if left_half[i] < right_half[j]: data[k] = left_half[i] i += 1 else: data[k] = right_half[j] j += 1 k += 1 while i < len(left_half): data[k] = left_half[i] i += 1 k += 1 while j < len(right_half): data[k] = right_half[j] j += 1 k += 1 data = [38, 27, 43, 3, 9, 82, 10] merge_sort(data) print("Sorted array:", data) # Output: Sorted array: [3, 9, 10, 27, 38, 43, 82] ``` The `merge_sort` function recursively divides the list until it's composed of single-element lists. The `merge` function (implicitly within the `while` loops) combines these sorted sublists efficiently.
Visual Demonstration of Merge Sort, How to Implement Sorting Algorithms in Python
Let's visualize the merge sort process using the example list [8, 3, 1, 7, 0, 10, 2].
Imagine a tree-like structure. The root represents the entire unsorted list. The first level of branching divides the list into [8, 3, 1, 7] and [0, 10, 2]. This continues recursively until we have single-element lists at the bottom: [8], [3], [1], [7], [0], [10], [2]. These are already sorted.
Now, the merging begins. The algorithm starts at the bottom, merging adjacent pairs: [3, 8], [1, 7], [0, 10], [2]. Then, it merges these pairs: [1, 3, 7, 8], [0, 2, 10]. Finally, the top-level merge combines these sorted sublists into the final sorted list: [0, 1, 2, 3, 7, 8, 10]. The visual is a binary tree where each node represents a sublist, and the leaves are the single-element sublists. The merging process moves upwards from the leaves to the root, combining the sorted sublists at each level. This visual representation clearly illustrates the divide-and-conquer nature of the algorithm and how the sorted sublists are progressively merged to produce the final sorted list.
Quicksort Implementation
Quicksort is a powerful divide-and-conquer sorting algorithm known for its efficiency in practice, often outperforming other algorithms like merge sort for many real-world datasets. Its speed comes from its clever partitioning strategy, which efficiently arranges elements around a chosen pivot. However, understanding its nuances and potential pitfalls is crucial for effective implementation.
Quicksort's core idea is to recursively partition the input array around a pivot element. The partition process rearranges the array such that all elements smaller than the pivot are placed before it, and all elements larger than the pivot are placed after it. This process is then recursively applied to the sub-arrays before and after the pivot until the entire array is sorted.
Partitioning Strategy in Quicksort
The partitioning strategy is the heart of Quicksort. A pivot element is selected (the choice of pivot significantly impacts performance, as discussed later), and the array is rearranged in-place. There are several ways to implement partitioning, but a common approach involves two pointers, one starting from the beginning of the array and the other from the end. The left pointer moves right until it finds an element greater than or equal to the pivot, and the right pointer moves left until it finds an element less than or equal to the pivot. If the left pointer's index is less than the right pointer's index, the elements at these indices are swapped. This process continues until the pointers cross, at which point the pivot is swapped with the element at the right pointer's index. This ensures all elements smaller than the pivot are to its left, and all elements larger are to its right.
Python Implementation of Quicksort
```python
def quicksort(arr):
if len(arr) < 2:
return arr
else:
pivot = arr[0]
less = [i for i in arr[1:] if i <= pivot]
greater = [i for i in arr[1:] if i > pivot]
return quicksort(less) + [pivot] + quicksort(greater)
```
This implementation uses a simple recursive approach. The pivot is chosen as the first element for simplicity. More sophisticated pivot selection strategies are discussed below. The list comprehension creates sub-arrays of elements less than or equal to and greater than the pivot. The recursive calls sort these sub-arrays, and the result is the concatenation of the sorted sub-arrays with the pivot in the middle.
Potential Issues and Mitigation Strategies in Quicksort
Quicksort's worst-case performance occurs when the pivot selection consistently results in highly unbalanced partitions. For instance, if the pivot is always the smallest or largest element, the algorithm degrades to O(n²) time complexity, similar to bubble sort. This is because each recursive call only reduces the problem size by one element. In the best-case scenario (balanced partitions at each step), it achieves O(n log n) time complexity.
To mitigate the worst-case scenario, several strategies can be employed:
Choosing a good pivot is key. Instead of always selecting the first element, consider:
- Random Pivot Selection: Randomly choosing the pivot from the array significantly reduces the likelihood of consistently unbalanced partitions. This approach makes the worst-case scenario much less probable in practice.
- Median-of-Three Pivot Selection: Selecting the median of the first, middle, and last elements as the pivot often leads to more balanced partitions than simply selecting the first element.
For very large datasets, consider switching to a different sorting algorithm (like merge sort or heapsort) when the recursion depth reaches a certain threshold. This helps prevent stack overflow errors and improves performance in extreme cases.
Another approach involves using an iterative implementation of quicksort, which eliminates the potential for stack overflow errors associated with deep recursion. However, iterative implementations are generally more complex to code.
Heapsort Implementation: How To Implement Sorting Algorithms In Python
Heapsort is a comparison-based sorting algorithm that leverages the heap data structure for efficient sorting. Unlike algorithms like quicksort or mergesort, which often rely on recursion, heapsort uses a bottom-up approach, making it particularly well-suited for situations where recursion might be less efficient or even problematic. Understanding heaps is key to grasping how heapsort works its magic.
A heap is a specialized tree-based data structure that satisfies the heap property: in a max-heap (the type typically used in heapsort), the value of each node is greater than or equal to the value of its children. This property ensures that the largest element is always at the root of the heap. This structure allows for efficient retrieval of the maximum element (O(1) time complexity) and efficient replacement of the maximum element with another element (O(log n) time complexity). This efficiency is what makes heapsort shine.
Heap Data Structure and its Relevance to Heapsort
The heap data structure's inherent properties are directly exploited by the heapsort algorithm. The process begins by building a max-heap from the unsorted input array. Once the heap is built, the algorithm repeatedly extracts the maximum element (the root) and places it at the end of the array, effectively sorting the array from largest to smallest. The remaining elements are then re-heapified to maintain the max-heap property, and the process is repeated until the entire array is sorted. This efficient extraction and re-heapification process leads to heapsort's performance advantages.
Python Implementation of Heapsort
Here's a Python implementation of the heapsort algorithm:
```python
import heapq
def heapsort(arr):
heapq.heapify(arr) # Build a min-heap in-place. We'll adapt later.
sorted_arr = []
while arr:
sorted_arr.append(heapq.heappop(arr)) #Extract smallest element
return sorted_arr[::-1] #Reverse to get a max-heap sorted array.
#Example usage
my_array = [12, 11, 13, 5, 6, 7]
sorted_array = heapsort(my_array)
print("Sorted array:", sorted_array)
```
Note: The `heapq` module in Python builds a *min-heap*. To achieve a max-heap sort, we build a min-heap and then reverse the resulting sorted array.
Performance Comparison of Heapsort with Merge Sort and Quicksort
Heapsort boasts a time complexity of O(n log n) in both average and worst-case scenarios. This consistent performance is a significant advantage over quicksort, which can degrade to O(n²) in its worst-case (though highly unlikely in practice with good pivot selection). Merge sort also has O(n log n) time complexity in both average and worst-case scenarios but often has a higher constant factor due to the overhead of creating and merging subarrays. In summary:
| Algorithm | Average Time Complexity | Worst-Case Time Complexity |
|---|---|---|
| Heapsort | O(n log n) | O(n log n) |
| Mergesort | O(n log n) | O(n log n) |
| Quicksort | O(n log n) | O(n²) |
The space complexity of heapsort is O(1) because it sorts in-place, unlike mergesort which requires O(n) extra space for merging. Therefore, for large datasets where memory is a concern, heapsort's space efficiency becomes a compelling factor. The choice between heapsort, mergesort, and quicksort often depends on the specific application and priorities (speed vs. guaranteed performance). For example, when guaranteed O(n log n) performance is critical, heapsort is preferred over quicksort.
Choosing the Right Algorithm
Picking the perfect sorting algorithm isn't about finding a "best" one – it's about finding the *right* one for your specific needs. Just like choosing the right tool for a job, selecting a sorting algorithm depends on several key factors: the size of your data, the type of data you're working with, and your performance requirements (how fast it needs to be). Ignoring these factors can lead to inefficient code that runs slower than necessary, or even crashes on large datasets.
Factors Influencing Algorithm Selection involve a careful consideration of data characteristics and performance expectations. The size of the dataset significantly impacts runtime. For smaller datasets, the overhead of more complex algorithms might outweigh their advantages. Data type also plays a role; some algorithms perform better with specific data types (e.g., integers versus strings). Finally, the application's performance requirements (speed, memory usage) dictate the algorithm's suitability. A real-time application demands a fast algorithm, while a batch process might tolerate a slower but simpler one.
Algorithm Selection Guidelines
This section provides practical guidelines for choosing the appropriate sorting algorithm based on the characteristics of the data and the application's requirements. Understanding these guidelines allows developers to optimize their code for performance and efficiency.
| Algorithm | Strengths | Weaknesses | Best Use Cases |
|---|---|---|---|
| Bubble Sort | Simple to understand and implement, in-place. | Very inefficient for large datasets; O(n^2) time complexity. | Educational purposes, very small datasets where simplicity is prioritized over speed. |
| Insertion Sort | Simple, efficient for small datasets or nearly sorted data, in-place. | Inefficient for large datasets; O(n^2) time complexity in the worst case. | Small datasets, nearly sorted data, situations where simplicity and in-place sorting are crucial. |
| Selection Sort | Simple, in-place, performs well with small datasets. | Inefficient for large datasets; O(n^2) time complexity. | Small datasets where simplicity and in-place sorting are important. |
| Merge Sort | Guaranteed O(n log n) time complexity, stable sort. | Requires extra space for merging (not in-place). | Large datasets where guaranteed performance is crucial, external sorting. Excellent for linked lists. |
| Quicksort | Generally very fast, O(n log n) average-case time complexity, in-place. | Worst-case time complexity is O(n^2), performance depends heavily on pivot selection. | Large datasets where speed is paramount, but there's a risk of performance degradation in worst-case scenarios (mitigated with good pivot selection strategies). |
| Heapsort | Guaranteed O(n log n) time complexity, in-place. | Can be slightly slower than Quicksort in practice. | Large datasets where guaranteed performance and in-place sorting are important. A good alternative to merge sort when space is a concern. |
Python's Built-in Sorting Function
Python offers incredibly efficient built-in methods for sorting, making life significantly easier for developers. Instead of wrestling with the complexities of implementing algorithms like quicksort or mergesort from scratch, you can leverage Python's optimized functions for speed and simplicity. This section dives into how to use these powerful tools and compares their performance to the algorithms we've explored previously.
Python provides two primary ways to sort sequences: the sorted() function, which returns a *new* sorted list, and the list.sort() method, which sorts a list *in-place*. Both offer flexibility through optional parameters for customization.
Using sorted() and list.sort()
The sorted() function takes an iterable (like a list, tuple, or string) as input and returns a new list containing all items from the iterable in ascending order. The original iterable remains unchanged. list.sort(), on the other hand, modifies the list directly; it doesn't return a new list, and the original list is altered.
Here's a simple example illustrating the difference:
my_list = [3, 1, 4, 1, 5, 9, 2, 6]
sorted_list = sorted(my_list) # sorted_list will be [1, 1, 2, 3, 4, 5, 6, 9]
print(f"Original list: my_list") # Output: Original list: [3, 1, 4, 1, 5, 9, 2, 6]
print(f"Sorted list: sorted_list") # Output: Sorted list: [1, 1, 2, 3, 4, 5, 6, 9]
my_list.sort() # my_list is now sorted in place
print(f"List after sort(): my_list") # Output: List after sort(): [1, 1, 2, 3, 4, 5, 6, 9]
Performance Comparison
Python's built-in sorting function, which uses Timsort (a hybrid sorting algorithm derived from merge sort and insertion sort), is highly optimized. In most cases, it will significantly outperform the simpler sorting algorithms we implemented (bubble sort, insertion sort, selection sort) for larger datasets. While the simpler algorithms are useful for educational purposes and understanding fundamental sorting concepts, they are not practical for real-world applications involving substantial data. For example, a bubble sort on a million-element list would take an impractically long time, while Python's built-in function would complete the task in a fraction of a second. The performance difference becomes increasingly pronounced as the dataset size grows. Merge sort and quicksort offer better average-case performance than the simpler algorithms, but Timsort is generally even faster and more robust in practice, handling various data distributions efficiently.
Using the key and reverse Parameters
Both sorted() and list.sort() accept optional key and reverse parameters to customize the sorting process.
The key parameter specifies a function to be called on each list element prior to making comparisons. This allows you to sort based on a specific attribute or transformation of the data. For example, to sort a list of strings by length:
strings = ["apple", "banana", "kiwi", "orange"]
sorted_strings = sorted(strings, key=len) # sorted by length
print(sorted_strings) # Output: ['kiwi', 'apple', 'orange', 'banana']
The reverse parameter, a boolean value, determines the sorting order. reverse=True sorts in descending order; otherwise, it sorts in ascending order (which is the default).
numbers = [3, 1, 4, 1, 5, 9, 2, 6]
descending_numbers = sorted(numbers, reverse=True)
print(descending_numbers) # Output: [9, 6, 5, 4, 3, 2, 1, 1]
Final Wrap-Up
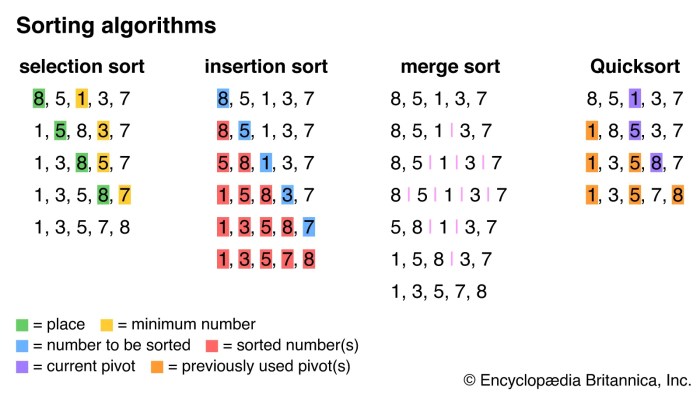
Source: britannica.com
Mastering sorting algorithms in Python is a crucial step in becoming a more efficient and effective programmer. From understanding the core concepts to implementing and comparing various techniques, this guide provides a comprehensive roadmap. Remember, the choice of algorithm often depends on the specific context—data size, data type, and performance requirements. So, equip yourself with this knowledge, experiment with different approaches, and watch your coding skills soar to new heights! Happy sorting!


{kind=link}