Exploring the World of Serverless Computing: Forget endless server management headaches! Dive into a revolutionary approach to application development where you ditch the servers and focus solely on your code. This isn’t some futuristic fantasy; serverless architecture is transforming how businesses build and scale applications, offering unparalleled flexibility and cost-effectiveness. We’ll unravel the mysteries behind this paradigm shift, from its core principles to advanced deployment strategies, showcasing real-world examples that’ll leave you wondering why you weren’t using it sooner.
This deep dive will cover everything from understanding the fundamental components of a serverless system—functions, triggers, and events—to mastering the intricacies of different serverless platforms like AWS Lambda, Azure Functions, and Google Cloud Functions. We’ll explore best practices for designing secure and scalable serverless applications, tackling crucial aspects like database integration, error handling, and efficient deployment. Get ready to unlock the power of serverless and build the next generation of applications.
Introduction to Serverless Computing
Serverless computing is revolutionizing how we build and deploy applications. It’s a cloud-based execution model where the cloud provider dynamically manages the allocation of computing resources, freeing developers from the complexities of server management. Instead of provisioning and managing servers, developers focus solely on writing and deploying code. This paradigm shift significantly impacts development speed, cost efficiency, and scalability.
Serverless computing operates on the core principles of event-driven architecture and automatic scaling. Applications are triggered by events, such as user requests or data changes, and the cloud provider automatically scales resources up or down based on demand. This eliminates the need for developers to predict and manage peak loads, resulting in significant cost savings and improved performance.
Benefits of Serverless Architecture
Adopting a serverless architecture offers several compelling advantages. The most significant benefit is reduced operational overhead. Developers no longer need to worry about server maintenance, patching, or scaling. This frees up valuable time and resources that can be dedicated to developing innovative features and improving the application’s core functionality. Cost optimization is another key advantage. With serverless, you only pay for the compute time your application consumes, eliminating the costs associated with idle servers. This pay-as-you-go model is particularly beneficial for applications with fluctuating workloads. Finally, improved scalability is inherent in serverless architectures. The cloud provider automatically scales resources to handle traffic spikes, ensuring your application remains responsive even under high demand.
Real-World Applications of Serverless Technologies
Serverless technologies are powering a wide range of applications across various industries. For instance, many companies use serverless functions for processing images uploaded by users. When a user uploads an image, a serverless function is triggered to resize, compress, and watermark the image before storing it. Another common use case is real-time data processing. Serverless functions can efficiently process streams of data from IoT devices, enabling applications such as smart home automation and predictive maintenance. Furthermore, backend APIs for mobile and web applications are frequently built using serverless functions. This allows for rapid development and deployment of APIs, enabling developers to focus on the core functionality of their applications. Finally, serverless functions are used extensively in machine learning applications, enabling efficient training and deployment of models.
Comparison of Serverless and Traditional Hosting Models
The following table highlights the key differences between serverless and traditional hosting models:
| Feature | Serverless | Traditional Hosting |
|---|---|---|
| Server Management | Managed by Cloud Provider | Managed by Developer/Operator |
| Scaling | Automatic, Event-Driven | Manual or Automated (with limitations) |
| Cost | Pay-as-you-go | Fixed cost, regardless of usage |
| Deployment | Fast and frequent | Can be slower and less frequent |
Key Components of a Serverless System
Serverless computing might sound like magic, but it’s built on a surprisingly straightforward foundation. Understanding its core components – functions, triggers, and events – is key to unlocking its power and efficiency. Think of it as a sophisticated assembly line, where each part plays a vital role in the overall process.
At its heart, a serverless system orchestrates the execution of small, independent units of code in response to specific events. This differs significantly from traditional server-based applications, where you manage servers continuously, even when they’re idle. Let’s delve into the specifics.
Exploring the world of serverless computing can feel like navigating a complex landscape, requiring careful planning and foresight. Just like architecting a robust cloud system, securing your family’s future demands a similar level of strategic thinking. That’s why understanding How to Build a Comprehensive Insurance Strategy for Your Family is crucial; it’s the bedrock upon which you build financial resilience, mirroring the scalable and reliable infrastructure you aim for in serverless architecture.
Back to serverless, remember: proper resource allocation is key to both.
Functions
Functions are the fundamental building blocks of serverless architectures. These are self-contained pieces of code, written in various programming languages (like Python, Node.js, Java, etc.), that perform a specific task. They’re event-driven, meaning they only execute when triggered by an event. This “pay-per-use” model eliminates the need to maintain constantly running servers, leading to significant cost savings. Imagine a function designed to resize images uploaded to a website; it only runs when a new image is uploaded, not constantly in the background.
Triggers and Events
Triggers are the mechanisms that initiate the execution of a function. An event is something that happens, like a file upload, a database update, or a user interaction. The trigger acts as a listener, waiting for a specific event to occur. Once the event happens, the trigger activates the corresponding function. For example, a new email arriving in an inbox could be the event, triggering a function to process and categorize that email.
Function-as-a-Service (FaaS)
FaaS is the delivery model that makes serverless computing possible. It’s a cloud-based service that allows developers to upload their functions and let the cloud provider handle the underlying infrastructure. This means you don’t worry about server management, scaling, or maintenance. The provider automatically scales your functions based on demand, ensuring your application remains responsive even during traffic spikes.
Serverless Platforms
Several major cloud providers offer serverless platforms, each with its own set of features and strengths.
| Platform | Provider | Key Features | Pricing Model |
|---|---|---|---|
| AWS Lambda | Amazon Web Services | Extensive integrations with other AWS services, wide range of supported runtimes, robust monitoring and logging. | Pay-per-request, based on execution time and memory usage. |
| Azure Functions | Microsoft Azure | Strong integration with other Azure services, support for various programming languages, easy deployment through DevOps pipelines. | Pay-per-execution, based on execution time and resources consumed. |
| Google Cloud Functions | Google Cloud Platform | Seamless integration with other GCP services, event-driven architecture, automatic scaling, and strong focus on containerization. | Pay-per-invocation, based on execution time and memory allocated. |
Pricing Models Comparison
The pricing models of major serverless platforms are generally similar, focusing on usage-based billing. They primarily charge based on the execution time of your functions and the amount of memory allocated to them. However, minor differences exist in pricing tiers, free tiers, and additional features that might influence the overall cost. For example, AWS Lambda might offer slightly different pricing for different regions, while Azure Functions might have specific pricing for integrations with other services. Careful consideration of your specific needs and usage patterns is crucial for choosing the most cost-effective platform.
Designing Serverless Applications
Building serverless applications requires a shift in thinking compared to traditional architectures. Instead of managing servers, you focus on the individual functions that make up your application. This approach offers significant advantages in scalability, cost-efficiency, and developer productivity, but it also introduces unique design considerations. Let’s explore how to effectively design and implement serverless applications.
Image Upload Processing Application Design
A simple serverless application for processing image uploads could be structured as follows: an API Gateway receives the image upload request, triggering a Lambda function. This Lambda function handles the upload, potentially resizing or modifying the image using a service like AWS Lambda Layers containing image processing libraries. The processed image is then stored in a cloud storage service like Amazon S3. Another Lambda function, triggered by the completion of the image processing, might update a database with metadata about the uploaded image (e.g., filename, size, URL). This design leverages the event-driven nature of serverless, allowing for efficient scaling based on demand. Each component is independently scalable and only consumes resources when actively processing requests.
Database Integration Considerations
Integrating databases with serverless applications requires careful planning. Traditional database connection methods might not be optimal due to the ephemeral nature of serverless functions. Using serverless-compatible databases, such as DynamoDB or managed services like Aurora Serverless, offers significant advantages. These services scale automatically based on demand and only charge for the resources consumed. Furthermore, consider using techniques like connection pooling to minimize the overhead of establishing database connections for each function invocation. Choosing the right database type – NoSQL (like DynamoDB) for high throughput and scalability or relational (like Aurora Serverless) for complex data relationships – is crucial for performance and cost optimization. For example, if you’re dealing with unstructured data like image metadata, DynamoDB’s flexibility might be preferable.
Managing State and Data Persistence
Serverless functions are stateless by nature; each invocation is independent. To maintain state or persist data across function invocations, several strategies are employed. One common approach is using a database (as discussed above). Another is leveraging external services like S3 for storing data persistently. For short-lived state, in-memory caching mechanisms within the function itself (if appropriate) can be used, but it’s crucial to understand that this data will be lost upon function termination. For example, a session ID could be stored in a database to track user activity across multiple function calls. The choice of method depends on the application’s requirements and the nature of the data.
Error and Exception Handling Strategies, Exploring the World of Serverless Computing
Robust error handling is crucial in serverless architectures. Since functions are independent, errors in one function shouldn’t cascade and affect others. Implement comprehensive error logging, utilizing services like CloudWatch to monitor function health and identify potential issues. Implement retry mechanisms for transient errors (e.g., network issues) to improve application resilience. Consider using dead-letter queues (DLQs) to capture messages that consistently fail processing. These queues can be monitored and investigated to diagnose and resolve persistent errors. Finally, design your functions to return meaningful error responses to clients, providing clear and informative feedback when issues arise. For instance, a well-structured error response could include an error code and a descriptive message, allowing clients to handle errors gracefully.
Security in Serverless Environments

Source: slidegeeks.com
Serverless computing offers incredible scalability and cost efficiency, but it introduces a unique set of security challenges. Because you’re often relying on a third-party provider to manage the underlying infrastructure, understanding and mitigating these risks is crucial for maintaining the integrity and confidentiality of your applications and data. This section dives into the key security considerations for serverless deployments.
Common Serverless Security Vulnerabilities
Serverless architectures, while abstracting away much of the infrastructure management, don’t eliminate security concerns. Instead, they shift the focus to different attack vectors. Understanding these vulnerabilities is the first step towards building secure serverless applications. For example, improper configuration of access controls can expose sensitive data or allow unauthorized access to functions. Insecure dependencies within your function code can introduce vulnerabilities, just like in traditional applications. Additionally, the shared responsibility model inherent in serverless computing means you need to be vigilant about your own code’s security and the security of the services you integrate with. Finally, insufficient logging and monitoring can make it difficult to detect and respond to security incidents effectively.
Securing Access to Serverless Functions and Data
Robust access control is paramount in serverless environments. This involves implementing granular permissions, limiting access to only the necessary resources, and employing the principle of least privilege. For instance, instead of granting broad permissions to a function, you should only grant it the specific permissions it needs to perform its task. This minimizes the potential damage if that function is compromised. Leveraging features like virtual private clouds (VPCs) and network security groups (NSGs) can further restrict access to your serverless functions and the underlying infrastructure. Regular security audits and penetration testing can identify and address vulnerabilities before they can be exploited.
Implementing Authentication and Authorization in Serverless Systems
Authentication verifies the identity of a user or service, while authorization determines what actions they are permitted to perform. In serverless, this often involves integrating with identity providers like AWS Cognito or Auth0. These services handle user management, authentication flows, and token generation. These tokens are then used to authorize access to serverless functions. This approach ensures that only authenticated and authorized users or services can access your functions and data. For example, an API Gateway can be configured to require authentication before forwarding requests to your backend functions. This prevents unauthorized access to sensitive resources. The implementation details will vary depending on the specific serverless platform and the security requirements of your application.
IAM Roles and Policies in Securing Serverless Deployments
Identity and Access Management (IAM) plays a critical role in securing serverless deployments. IAM roles provide temporary security credentials to your serverless functions, allowing them to access other AWS services without needing long-term access keys. IAM policies define what actions a role or user is allowed to perform. By carefully crafting these policies, you can grant functions only the minimum necessary permissions, minimizing the blast radius of a potential compromise. Using least privilege principles in IAM policies helps prevent unintended access and improves the overall security posture of your serverless architecture. Regular reviews of IAM roles and policies are essential to ensure they remain aligned with your security requirements and to remove any unnecessary permissions.
Serverless Deployment and Management

Source: alignminds.com
So, you’ve designed your killer serverless application. Now what? Deployment and ongoing management are crucial for ensuring your application runs smoothly, scales effectively, and remains secure. This section dives into the nitty-gritty of getting your code into production and keeping it humming.
The process of deploying a serverless application isn’t a one-size-fits-all affair. It heavily depends on your chosen cloud provider (AWS Lambda, Google Cloud Functions, Azure Functions, etc.) and the tools you’re using. However, the core principles remain consistent: packaging your code, configuring settings, and deploying to the chosen platform. Think of it like baking a cake – you need the right ingredients (code, configurations), the right oven (cloud platform), and the right instructions (deployment process).
Serverless Application Deployment Process
Deploying a serverless application typically involves these steps: First, you package your code and dependencies into a deployable unit (e.g., a zip file for AWS Lambda). Next, you configure your function’s settings, including memory allocation, timeout limits, and environment variables. Then, you use the provider’s tools (CLI, console, or CI/CD pipeline) to upload the package and configure the function. Finally, you test the deployment thoroughly to ensure everything is working as expected. For instance, deploying a Node.js function to AWS Lambda might involve using the AWS Serverless Application Model (SAM) CLI to package, configure, and deploy your code. The process is similar for other platforms, with minor variations in tooling and commands.
Monitoring and Logging Serverless Functions
Effective monitoring and logging are essential for identifying and resolving issues quickly. Cloud providers offer robust monitoring and logging services integrated with their serverless platforms. These services provide insights into function execution times, error rates, and resource consumption. For example, AWS CloudWatch provides metrics and logs for Lambda functions, allowing you to track invocation counts, duration, errors, and more. Similarly, Google Cloud Monitoring and Logging offer comparable functionalities for Google Cloud Functions. By setting up alerts based on key metrics (e.g., high error rates, prolonged execution times), you can proactively address potential problems before they impact users.
Best Practices for Managing the Lifecycle of Serverless Functions
Managing the lifecycle of serverless functions involves version control, testing, deployment, and updates. Utilizing version control systems like Git is crucial for tracking changes and enabling rollbacks if necessary. Implementing a robust testing strategy (unit tests, integration tests) ensures the quality and reliability of your functions. Continuous integration and continuous deployment (CI/CD) pipelines automate the deployment process, improving efficiency and reducing errors. Regularly reviewing and updating your functions is also vital to address security vulnerabilities, improve performance, and incorporate new features. Consider using Infrastructure as Code (IaC) tools like Terraform or CloudFormation to manage your serverless infrastructure. This allows for consistent and repeatable deployments and simplifies infrastructure management.
Scaling Serverless Applications Efficiently
One of the biggest advantages of serverless is its inherent scalability. Serverless platforms automatically scale your functions based on demand, ensuring your application can handle traffic spikes without manual intervention. This auto-scaling is handled by the underlying infrastructure, freeing you from the complexities of managing servers. For example, if a Lambda function receives a sudden surge in requests, the platform automatically provisions additional instances to handle the load. However, understanding the scaling behavior of your functions is still important. Optimizing your function code for efficiency can reduce costs and improve performance. Properly configuring memory allocation and timeout settings can also impact scaling behavior and cost optimization. Monitoring your application’s scaling behavior through metrics and logs is crucial to fine-tune your configuration and ensure optimal performance and cost-effectiveness.
Advanced Serverless Concepts: Exploring The World Of Serverless Computing
So you’ve grasped the basics of serverless – congrats! But the real power lies in understanding its advanced applications. We’re diving deep into how serverless tackles complex architectures and real-time challenges, pushing the boundaries of what’s possible. Get ready to level up your serverless game.
Serverless Containers
Serverless containers combine the benefits of containerization with the serverless model. Instead of managing individual servers, developers package their applications within containers (like Docker images) and deploy them to a serverless platform. This approach offers improved portability, consistency, and resource isolation compared to traditional serverless functions. Imagine deploying a complex application with multiple dependencies – containers simplify this process significantly, ensuring that all required components are bundled together and run consistently across different environments. The platform then manages the underlying infrastructure, scaling containers based on demand, similar to how it manages individual functions. This leads to improved resource utilization and cost optimization.
Serverless for Microservices Architecture
Microservices architectures, characterized by breaking down applications into small, independent services, are a natural fit for serverless. Each microservice can be deployed as a serverless function or a containerized serverless application, allowing for independent scaling and deployment. This granular control simplifies development, testing, and deployment, allowing teams to work independently on different parts of the application. For example, an e-commerce platform could have separate microservices for product catalog, order processing, payment gateway, and user authentication, each deployed and scaled independently based on demand. This modularity also improves fault isolation – if one microservice fails, it doesn’t necessarily bring down the entire application.
Serverless in Event-Driven Architectures
Serverless shines in event-driven architectures. Events, such as database updates, file uploads, or user actions, trigger serverless functions to perform specific tasks. This asynchronous approach enables highly scalable and responsive applications. Consider a social media platform: a new post event could trigger functions to update user feeds, send notifications, and perform analytics, all happening concurrently and independently. This reactive approach allows the system to handle a massive influx of events without performance degradation, efficiently utilizing resources only when necessary. The decoupling of services also enhances resilience and maintainability.
Serverless for Real-Time Applications
While traditionally associated with background tasks, serverless is increasingly used for real-time applications. By leveraging technologies like WebSockets and serverless platforms with real-time capabilities, developers can build highly scalable and responsive applications. A chat application, for instance, can use serverless functions to handle message routing, presence updates, and user authentication, all in real-time. The platform automatically scales resources based on the number of concurrent users, ensuring a consistent and low-latency experience. This allows developers to focus on building the core application logic without worrying about the underlying infrastructure. The platform’s inherent scalability ensures the application can handle a surge in users without performance issues.
Serverless Use Cases and Examples
Serverless architecture isn’t just a buzzword; it’s a powerful tool transforming how businesses operate. Its ability to scale automatically and only charge for actual usage makes it incredibly cost-effective and efficient for a wide range of applications. Let’s explore some real-world examples across various industries.
The flexibility and scalability offered by serverless computing are proving invaluable across many sectors. By abstracting away server management, developers can focus on building innovative features and scaling their applications seamlessly to meet fluctuating demand. This leads to faster development cycles, reduced operational overhead, and ultimately, a better user experience.
Industries Utilizing Serverless Technologies
Serverless technologies have found a home in a diverse range of industries, each leveraging its unique strengths to optimize operations and deliver innovative solutions. The following examples showcase the versatility and impact of serverless computing.
- E-commerce: Companies like Amazon use serverless functions to handle peak traffic during sales events like Black Friday and Cyber Monday. This ensures their website remains responsive and prevents crashes, even under immense load.
- Media & Entertainment: Netflix utilizes serverless functions for video encoding and transcoding, allowing them to efficiently process and deliver content to millions of users globally. The scalability of serverless ensures consistent streaming quality regardless of concurrent viewers.
- Fintech: Payment processors employ serverless functions to handle real-time transactions, ensuring speed and security. The event-driven nature of serverless allows for rapid processing of payments, minimizing latency and improving customer experience.
- Healthcare: Serverless functions are used to process medical images and analyze patient data securely and efficiently. The scalability allows for handling large volumes of data, crucial for research and improved diagnostics.
- IoT: Serverless functions are ideal for processing data from connected devices. Their scalability allows for handling millions of devices simultaneously, essential for applications like smart homes and industrial automation.
Specific Serverless Application Examples
Let’s delve deeper into specific examples to see how serverless improves efficiency and scalability.
- E-commerce: Image resizing. An e-commerce platform might use a serverless function triggered by an image upload. This function automatically resizes the image to various dimensions (thumbnails, product page images, etc.) without requiring constant server resources. This improves website loading times and reduces storage costs.
- Media & Entertainment: Video processing pipeline. A serverless architecture can manage the complex workflow of video processing, from encoding to transcoding to content delivery. Each step is a separate function, triggered by the completion of the previous one. This allows for parallel processing and efficient scaling based on demand.
- Fintech: Fraud detection. Serverless functions can analyze transaction data in real-time to detect fraudulent activity. The event-driven nature of serverless allows for immediate responses to suspicious transactions, minimizing financial losses.
- Healthcare: Patient data analysis. Serverless functions can analyze patient data from various sources (wearable devices, medical records, etc.) to identify trends and patterns. The scalability of serverless allows for processing massive datasets, enabling better disease prediction and personalized medicine.
- IoT: Real-time sensor data processing. A serverless function triggered by sensor data from an IoT device can perform real-time analysis and trigger actions based on predefined thresholds. For example, a smart thermostat can automatically adjust temperature based on occupancy and external weather conditions.
Improved Efficiency and Scalability
The benefits of serverless are clear in these examples. The key improvements are:
- Cost Optimization: Pay only for compute time used, eliminating wasted resources on idle servers.
- Scalability: Automatically scale up or down based on demand, handling traffic spikes without performance degradation.
- Increased Agility: Faster development cycles due to simplified infrastructure management.
- Enhanced Reliability: Built-in fault tolerance and high availability features.
The Future of Serverless Computing
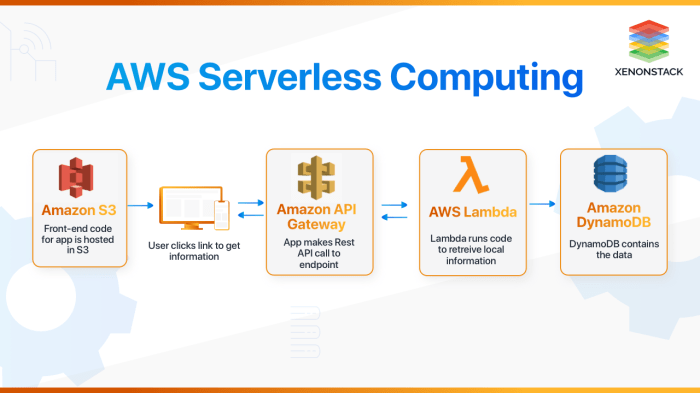
Source: xenonstack.com
Serverless computing, once a niche technology, is rapidly becoming mainstream. Its promise of scalability, cost-efficiency, and developer agility is driving widespread adoption across various industries. However, the journey is far from over; the future of serverless is brimming with exciting developments, potential hurdles, and fascinating predictions.
Serverless architectures are constantly evolving, adapting to the ever-changing landscape of cloud computing and software development. Several key trends are shaping its future trajectory, impacting how developers build, deploy, and manage applications.
Emerging Trends and Technologies
The serverless landscape is witnessing a surge in innovation. We’re seeing the rise of more sophisticated serverless platforms offering enhanced features and functionalities. For example, advancements in event-driven architectures are enabling more complex and responsive applications. The integration of AI and machine learning within serverless functions is also gaining traction, automating tasks and improving application intelligence. Furthermore, the development of serverless-native databases and other services is simplifying application development and reducing operational overhead. The increasing focus on edge computing is also expanding the reach of serverless, allowing for faster response times and lower latency in applications closer to users. Companies like AWS, Google Cloud, and Azure are continuously releasing new features and services to enhance the serverless experience. For instance, improvements in cold start performance and enhanced debugging tools are making serverless development more streamlined.
Potential Challenges and Limitations
Despite its advantages, serverless architecture isn’t without its challenges. One significant hurdle is vendor lock-in. Migrating applications between different serverless platforms can be complex and time-consuming. Another concern is debugging and monitoring serverless applications. The distributed nature of serverless functions can make it difficult to trace errors and understand application behavior. Security is also a crucial consideration. Protecting data and ensuring the security of serverless functions requires careful planning and implementation of robust security measures. Furthermore, the operational overhead associated with managing a large number of serverless functions can be significant. Careful planning and the use of appropriate tools are essential for efficient management. Finally, cold starts, the delay experienced when a serverless function is invoked for the first time, remain a concern and actively researched area for improvement. Strategies like function warm-up and optimized code are employed to mitigate this issue.
Predictions on the Future Evolution of Serverless Technologies
The future of serverless computing looks bright. We can anticipate increased adoption across diverse sectors, from enterprise applications to IoT devices. The development of more sophisticated tools and frameworks will simplify serverless development, making it accessible to a wider range of developers. Serverless will become increasingly integrated with other cloud services, creating a more cohesive and efficient cloud ecosystem. We expect to see further advancements in serverless security, with more robust tools and techniques to protect applications and data. Moreover, the integration of serverless with edge computing will enable the development of highly responsive and geographically distributed applications. The convergence of serverless and AI/ML will lead to the creation of intelligent and self-managing applications. Finally, we predict the emergence of new serverless paradigms and architectures that further optimize performance, scalability, and cost-efficiency. For instance, the rise of serverless containers and serverless functions running on WebAssembly may become prevalent, allowing for greater portability and efficiency.
Final Thoughts
So, there you have it—a whirlwind tour through the exciting world of serverless computing. From its core concepts to its advanced applications, we’ve explored the potential of this transformative technology. While there are challenges to overcome, the benefits—scalability, cost efficiency, and developer agility—are undeniable. As serverless technology continues to evolve, its impact on the tech landscape will only intensify. Embrace the change, embrace serverless, and prepare to build the future of applications, one function at a time.

{kind=link}