Writing Clean Code: Best Practices Every Developer Should Know – sounds boring, right? Wrong! Clean code isn’t just about aesthetics; it’s the secret weapon for building robust, maintainable, and collaborative software. Think of it as the difference between a chaotic kitchen and a perfectly organized one – both might produce a meal, but one is far more efficient and enjoyable. This guide dives into the essential practices that will transform your coding from messy to masterful.
We’ll cover everything from naming conventions and code formatting to error handling and testing methodologies. Prepare to level up your coding game and say goodbye to those late-night debugging sessions fueled by caffeine and desperation. Get ready to write code that’s not just functional, but beautiful.
Introduction to Clean Code Principles
Clean code isn’t just about making your code look pretty; it’s a fundamental practice that significantly impacts the entire software development lifecycle. Think of it as writing a well-structured essay – clear, concise, and easy to understand. Writing clean code ensures your projects are easier to maintain, collaborate on, and ultimately, less prone to bugs. The benefits extend far beyond the initial coding phase, saving time and headaches down the line.
Clean code adheres to several core tenets. It prioritizes readability, meaning anyone familiar with the language should be able to grasp the code’s purpose and functionality without significant effort. It also emphasizes simplicity; complex logic should be broken down into smaller, manageable modules. Furthermore, clean code is well-documented, providing clear explanations of its functionality and purpose. Finally, it follows consistent coding conventions, ensuring uniformity across the project. Ignoring these principles can lead to a chaotic mess that’s difficult to work with.
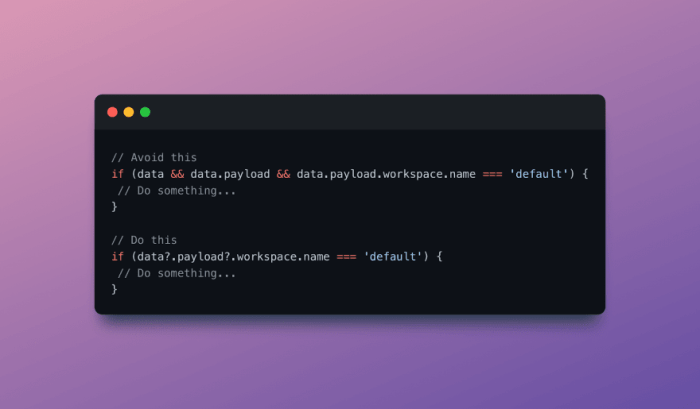
Examples of Unclean Code
Let’s illustrate the difference with some examples. Imagine a function named `calculateTotalPrice` that’s crammed with nested `if-else` statements, handling various discounts and taxes without any clear separation of concerns. This makes the code hard to understand, debug, and modify. A better approach would be to break down the calculation into smaller, more focused functions – one for calculating discounts, another for taxes, and a final one to combine the results. This modular approach significantly enhances readability and maintainability. Another example is a function with a name that doesn’t accurately reflect its purpose, like a function named `doStuff()` which actually performs complex database operations. This lack of descriptive naming makes it difficult for other developers (or even your future self) to understand the function’s role without delving into the code itself.
Long-Term Benefits of Clean Code
The long-term benefits of clean code are substantial. Maintainability is paramount; clean code is much easier to update, debug, and extend. Imagine needing to add a new feature to a large project. If the code is messy and poorly structured, this seemingly simple task can become a nightmare. With clean code, however, modifications are straightforward and less prone to introducing new bugs. Readability ensures smooth collaboration. When multiple developers work on the same project, clean code makes it easier for them to understand each other’s work, reducing conflicts and improving team efficiency. This also simplifies onboarding new team members, as they can quickly grasp the project’s structure and functionality. Finally, clean code reduces the risk of bugs. Clear, well-structured code is easier to test and review, leading to fewer errors and improved software quality. Consider a large project with a deadline looming – a clean codebase allows for faster debugging and troubleshooting, ultimately saving time and resources.
Naming Conventions and Readability
Writing clean code isn’t just about making your program work; it’s about making it understandable, maintainable, and – dare we say – enjoyable to read. A crucial aspect of this is choosing the right names for your variables, functions, and classes. Think of it like this: would you rather read a recipe with ingredients labeled “stuff1,” “thing2,” and “mystery powder,” or one with clear, descriptive names like “all-purpose flour,” “granulated sugar,” and “baking soda”? The answer is obvious. Let’s dive into the art of naming in coding.
Well-chosen names act as self-documenting code. They reduce the need for extensive comments, making your code easier to understand at a glance. Inconsistent or poorly chosen names, on the other hand, create confusion and increase the time spent debugging and maintaining your projects. This translates directly to wasted time and potential errors down the line – nobody wants that, right?
Best Practices for Naming
Effective naming follows a few key principles: be descriptive, be concise, and be consistent. Descriptive names clearly indicate the purpose of a variable, function, or class. Concise names avoid unnecessary verbosity. Consistency ensures that similar elements are named in a similar way throughout your project. Let’s look at some examples.
Writing clean code isn’t just about aesthetics; it’s about building robust, maintainable software. Just like you need a solid safety net, and that means protecting your investment – much like ensuring you have the right auto insurance, as explained in this helpful guide Why You Need Auto Insurance to Protect Your Vehicle and Passengers , to safeguard against unforeseen circumstances.
Similarly, clean code minimizes future headaches and ensures your project runs smoothly. So, prioritize those best practices!
| Feature | Good Name | Bad Name | Explanation |
|---|---|---|---|
| Variable | customerName |
cn |
Clear and descriptive vs. cryptic and unclear. |
| Function | calculateTotalPrice() |
calc() |
Precisely describes the function’s action vs. vague and ambiguous. |
| Class | ShoppingCart |
sc |
Clearly identifies the class’s purpose vs. an abbreviation that requires context. |
| Boolean Variable | isCustomerLoggedIn |
loggedIn |
Clearly indicates a boolean value and its meaning vs. less clear. |
Imagine working on a project where variables are named things like `x`, `y`, `z`, or `data`. Without detailed comments (which, let’s be honest, often get outdated), understanding the code becomes a tedious, error-prone process. Conversely, using descriptive names like `customerAge`, `productPrice`, or `orderTotal` instantly conveys meaning, making the code significantly more readable and maintainable. This directly impacts development speed and reduces the risk of introducing bugs.
Impact of Consistent Naming
Consistency is the unsung hero of clean code. Imagine a project where some functions use camel case (calculateTotal), others use underscores (calculate_total), and still others use Hungarian notation (intTotalAmount). The cognitive load on the developer trying to understand the code increases exponentially. Consistent naming, on the other hand, creates a predictable and harmonious codebase, making it easier to navigate and understand. This translates to faster development, fewer errors, and a more pleasant coding experience overall.
Code Formatting and Style Guides
Writing clean code isn’t just about functionality; it’s about readability and maintainability. Imagine trying to decipher a messy, inconsistent codebase – a nightmare, right? That’s where code formatting and style guides come in. They’re the unsung heroes of collaborative development, ensuring everyone’s on the same page and making the codebase a joy (or at least, a less painful experience) to work with.
Consistent formatting is crucial for improving code readability and reducing errors. Think of it like grammar and punctuation in writing – it might seem trivial, but inconsistent application makes the text difficult to understand. Similarly, inconsistent indentation, spacing, and line breaks in code can lead to confusion, bugs, and ultimately, a frustrating development process. Adopting a style guide provides a common framework, leading to a more uniform and understandable codebase, especially within a team environment.
The Importance of Consistent Indentation, Spacing, and Line Breaks
Consistent indentation clearly shows the structure of your code, highlighting blocks of code, loops, and conditional statements. Proper spacing improves readability by separating different parts of your code, making it easier to distinguish variables, operators, and s. Strategic line breaks prevent lines from becoming excessively long and improve overall readability. Imagine a wall of text versus paragraphs with clear breaks – the latter is much easier to digest. The same applies to code. For instance, overly long lines can be broken logically after operators or s to enhance readability. The key is to maintain consistency throughout the project to ensure a unified look and feel.
Popular Code Style Guides
Numerous style guides exist, each with its own conventions. PEP 8 is the widely accepted style guide for Python, dictating rules on indentation (4 spaces), line length (79 characters), naming conventions, and more. Other popular guides include Google Java Style Guide for Java, Airbnb JavaScript Style Guide for JavaScript, and many others specific to different programming languages. Adhering to these established guides ensures consistency and facilitates collaboration, as developers are familiar with the common practices. Following a style guide also makes it easier for others (or your future self!) to understand and maintain your code.
Examples of Good and Poor Code Formatting, Writing Clean Code: Best Practices Every Developer Should Know
Here’s an example of poorly formatted Python code:
def myfunction(x,y):
z=x+y
return z
print(myfunction(2,3))
This code is cramped and difficult to read. Now, let’s see the same function with proper formatting according to PEP 8:
def my_function(x, y):
z = x + y
return z
print(my_function(2, 3))
The improved version uses consistent indentation (4 spaces), clear spacing around operators, and meaningful variable names, significantly enhancing readability. The difference is night and day. This illustrates the impact of consistent formatting on code clarity. This improved version adheres to PEP 8 guidelines and is significantly more readable and maintainable.
Comments and Documentation: Writing Clean Code: Best Practices Every Developer Should Know
Clean code isn’t just about elegant syntax; it’s also about clear communication. Comments and documentation are crucial for making your code understandable, maintainable, and, frankly, less frustrating for everyone involved – including your future self. Think of them as the guidebook to your code’s inner workings.
Effective comments explain *why* the code does something, not *what* it does. The code itself should clearly show the *what*. Over-commenting can actually make your code harder to read, so focus on adding value, not noise.
Effective Commenting Practices
Good comments act as concise explanations for complex logic or non-obvious decisions. They clarify the intent behind a piece of code, particularly when dealing with intricate algorithms or tricky edge cases. They shouldn’t reiterate what the code already says explicitly.
Good Example:
// Calculate the Fibonacci sequence using dynamic programming to improve performance.
This comment explains *why* dynamic programming is used – a crucial piece of information not immediately apparent from the code itself.
Bad Example:
// This loop iterates through the array.
This comment is redundant; the loop’s purpose is already obvious from the code. It adds no value and clutters the code.
Function and Class Documentation Guidelines
Well-documented functions and classes are essential for larger projects. A consistent approach ensures everyone understands how to use your code. We’ll use a simplified, yet effective, approach here.
For functions, document the purpose, parameters, return values, and any potential exceptions. Consider using a format like this:
/
* Calculates the factorial of a given number.
*
* @param number n The number to calculate the factorial of. Must be a non-negative integer.
* @returns number The factorial of n. Returns 1 if n is 0.
* @throws Error If n is negative or not an integer.
*/
function factorial(n) ...
For classes, document the purpose of the class, its properties (with data types and descriptions), and its methods (using the function documentation style above). Clearly explain the overall design and intended use of the class. This makes it significantly easier for other developers (or even your future self) to understand and utilize your code effectively, preventing hours of debugging and frustration. Consider adding examples demonstrating common usage scenarios.
Functions and Methods

Source: middleware.io
Writing clean code isn’t just about making your code look pretty; it’s about making it maintainable, understandable, and less prone to bugs. A significant part of this involves crafting well-structured functions and methods. Think of functions as the building blocks of your program – if the blocks are messy and oversized, your entire structure will be shaky.
Functions should be small, focused, and do one thing, and one thing only. This is the essence of the Single Responsibility Principle, a cornerstone of clean code. By adhering to this principle, you create functions that are easier to understand, test, and reuse. Imagine trying to debug a 500-line function versus a series of 10-20 line functions – the latter is significantly less daunting.
The Single Responsibility Principle in Function Design
The Single Responsibility Principle (SRP) dictates that every function should have one, and only one, reason to change. If a function handles multiple unrelated tasks, it becomes difficult to modify it without introducing unintended consequences. For example, a function that both fetches data from a database *and* formats that data for display violates SRP. It should be split into two functions: one for data fetching and another for formatting. This improves modularity, making your code more flexible and easier to maintain. A well-structured function is easily testable in isolation, a crucial aspect of robust software development.
Anti-Patterns in Function Design
Overly long functions are a classic anti-pattern. These behemoths are often difficult to understand and debug. They often hide subtle bugs within their labyrinthine logic. Another common anti-pattern is functions with multiple exit points (multiple `return` statements). While sometimes unavoidable, excessive use of multiple return statements can make the flow of logic harder to follow and potentially lead to errors. Functions that modify global variables outside their scope can also create unexpected side effects and make the code harder to reason about.
Refactoring Large Functions
Let’s say you have a monster function, perhaps named `processUserData`, that handles user registration, data validation, database insertion, and email notification. This violates SRP. To refactor it, we break it down into smaller, more focused functions:
* `validateUserData`: Validates user input.
* `registerUser`: Inserts user data into the database.
* `sendWelcomeEmail`: Sends a welcome email to the new user.
Now, `processUserData` becomes a simple orchestrator:
“`python
def processUserData(userData):
validatedData = validateUserData(userData)
if validatedData:
registerUser(validatedData)
sendWelcomeEmail(validatedData)
“`
Each smaller function now has a single responsibility, making the code easier to understand, test, and maintain. This approach promotes better code organization and reduces the risk of introducing bugs during modifications. This modular approach allows for independent testing and easier debugging. If a problem occurs, you immediately know which function to investigate.
Code Reviews and Collaboration
Writing clean code isn’t a solo mission; it’s a team sport. Think of it like crafting a delicious meal – one amazing chef can’t do it all. You need a sous chef to check seasoning, a pastry chef for the perfect dessert, and even a sommelier to pair it all with the right wine. Code reviews are that crucial second (or third, or fourth!) pair of eyes, ensuring your culinary creation (aka, your code) is top-notch.
Effective code reviews are vital for maintaining code quality. They act as a safety net, catching potential bugs, design flaws, and security vulnerabilities before they reach production. Beyond bug hunting, they’re a powerful tool for knowledge sharing and team growth, fostering a culture of continuous learning and improvement within the development team. This collaborative process elevates everyone’s coding skills, creating a more robust and maintainable codebase.
Best Practices for Conducting Effective Code Reviews
Effective code reviews aren’t about finding fault; they’re about collaborative improvement. Focus on the code, not the coder. Keep the tone constructive and respectful, offering specific suggestions rather than broad criticisms. Limit the scope of each review to manageable chunks, focusing on one feature or a specific module at a time. This prevents review fatigue and ensures thorough examination. Use a structured approach, following a checklist to maintain consistency and avoid overlooking critical aspects.
Key Aspects to Focus On During Code Reviews
Before diving into a code review, establish a clear understanding of the code’s purpose and functionality. This provides context and helps identify potential deviations from the intended design. Then, systematically examine the following:
- Readability: Is the code easy to understand? Are variable names clear and descriptive? Is the code well-structured and logically organized? A good rule of thumb is: if someone else can’t easily understand your code, it needs improvement.
- Maintainability: Is the code well-documented? Is it modular and easily extensible? Could future modifications be made without significant effort? Think about the long-term implications – how easy will it be to update or debug this code six months from now?
- Efficiency: Is the code optimized for performance? Are there any unnecessary computations or redundant operations? Are appropriate data structures used? Consider both computational efficiency and memory usage. For instance, using a hash map instead of a linear search can dramatically improve performance for large datasets.
Testing and Unit Tests
Writing clean code isn’t just about aesthetics; it’s about building robust and maintainable software. A crucial element in achieving this is thorough testing, and unit testing forms the bedrock of a strong testing strategy. Unit tests verify individual components of your codebase, ensuring each part works as expected before they’re integrated into larger systems. This prevents the accumulation of small bugs that can later become massive headaches.
Testing allows developers to catch errors early in the development lifecycle, significantly reducing debugging time and costs. Imagine building a house without checking the strength of each brick – the entire structure could collapse. Similarly, untested code is a risky foundation for any software project. Comprehensive testing also provides confidence when refactoring or making changes to existing code, as you can quickly verify that modifications haven’t introduced new issues.
Unit Testing Examples
Let’s illustrate unit testing with a simple Python function that calculates the area of a rectangle:
“`python
def calculate_rectangle_area(length, width):
“””Calculates the area of a rectangle.”””
if length <= 0 or width <= 0:
raise ValueError("Length and width must be positive values.")
return length * width
```
A corresponding unit test using the `unittest` framework might look like this:
```python
import unittest
class TestRectangleArea(unittest.TestCase):
def test_positive_values(self):
self.assertEqual(calculate_rectangle_area(5, 10), 50)
def test_zero_values(self):
with self.assertRaises(ValueError):
calculate_rectangle_area(0, 5)
def test_negative_values(self):
with self.assertRaises(ValueError):
calculate_rectangle_area(-5, 10)
if __name__ == '__main__':
unittest.main()
```
This test suite covers several scenarios: positive inputs, zero inputs (which should raise a ValueError), and negative inputs (also raising a ValueError). This ensures the function behaves correctly under various conditions. Each test case isolates a specific aspect of the function's behavior, making it easier to pinpoint the source of any failures.
Testing Methodologies and Frameworks
Different testing methodologies cater to various needs and project scales. Unit testing, as shown above, focuses on individual units of code. Integration testing verifies the interaction between different units, while system testing assesses the entire system as a whole. Beyond these, there are also acceptance tests, which ensure the software meets user requirements, and performance tests, focusing on speed and efficiency.
Numerous testing frameworks exist, each with its strengths and weaknesses. `JUnit` is a popular choice for Java, while Python offers `unittest` (as shown above), `pytest`, and `nose2`. JavaScript developers frequently use `Jest` or `Mocha`. The choice of framework often depends on the programming language, project size, and team preferences. However, the core principles of testing remain consistent across frameworks: write clear, concise, and comprehensive tests that cover a wide range of scenarios. The goal is to create a safety net that catches errors before they reach production.
Refactoring and Code Optimization
Source: cloudinary.com
Writing clean code isn’t just about making it look pretty; it’s about building a sustainable and efficient codebase. This is where refactoring and code optimization come into play, ensuring your code remains robust and performant over time. Think of it as regularly servicing your car – neglecting maintenance leads to breakdowns, and neglecting your code leads to technical debt and headaches.
Refactoring is the process of restructuring existing computer code—changing the factoring—without changing its external behavior. It’s about improving the internal structure of your code to make it more readable, maintainable, and efficient. This isn’t about adding new features; it’s about improving the foundation. The benefits are numerous: reduced bugs, improved readability, enhanced maintainability, and ultimately, increased developer productivity. A well-refactored codebase is easier to understand, modify, and extend, saving time and effort in the long run.
Common Refactoring Techniques
Refactoring involves a series of small, incremental changes. These changes, when applied correctly, lead to significant improvements. Here are some common techniques:
- Extract Method: Breaking down large, complex methods into smaller, more manageable ones. This improves readability and makes testing easier. For example, a method calculating a complex tax might be split into separate methods for calculating individual components of the tax.
- Rename Method/Variable: Choosing clear and descriptive names for methods and variables. This dramatically enhances readability and makes the code’s intent immediately obvious. Instead of `calculateSomething()`, use `calculateTotalTax()`.
- Move Method: Relocating a method to a more appropriate class. This improves code organization and reduces dependencies between classes. If a method is closely related to another class, moving it can improve clarity and modularity.
- Introduce Explaining Variable: Creating new variables to store intermediate results, making complex expressions easier to understand. Instead of a long, convoluted calculation, break it into smaller parts with clear variable names explaining each step.
- Extract Class: Separating a large class into smaller, more focused classes. This improves code organization and reduces complexity. For example, a class handling both user authentication and profile management could be separated into distinct classes.
Improving Code Efficiency Without Sacrificing Readability
Optimizing code for efficiency is crucial, but it shouldn’t come at the cost of readability. The goal is to find a balance. Premature optimization is often detrimental; focus on writing clean, readable code first, then optimize only where necessary, using profiling tools to identify bottlenecks.
For example, consider nested loops. If you have a nested loop processing a large dataset, and profiling reveals it’s the performance bottleneck, you might explore alternative algorithms or data structures. Using a hash table instead of a linear search can drastically improve performance. However, ensure that the changes made are well documented and maintain the overall readability of the code. Avoid overly clever or cryptic optimizations that make the code difficult to understand. Clarity and maintainability should always take precedence. Remember, the cost of fixing a poorly optimized, hard-to-understand piece of code is far greater than the cost of writing clean, efficient code in the first place.
Version Control and Collaboration Tools

Source: medium.com
Clean code is a team effort. Writing pristine code is only half the battle; effectively managing and collaborating on that code is just as crucial. This is where version control systems, like Git, become indispensable tools for any development team, big or small. They not only track changes but also facilitate seamless collaboration and help prevent the chaos that can arise from multiple developers working on the same codebase simultaneously.
Version control systems provide a comprehensive history of your project’s evolution, allowing you to revert to previous versions if needed, experiment with new features without risking the stability of the main codebase, and easily track down the source of bugs. Imagine trying to manage a large project with multiple developers without version control—it’s akin to navigating a maze blindfolded.
Branching Strategies in Collaborative Development
Effective branching strategies are essential for managing concurrent development in a collaborative environment. A well-defined branching strategy minimizes conflicts and ensures a smooth workflow. Common strategies include Gitflow, GitHub Flow, and GitLab Flow, each offering a slightly different approach to managing branches. For example, Gitflow utilizes distinct branches for development, feature implementation, releases, and hotfixes, providing a structured approach to managing different stages of the software development lifecycle. In contrast, GitHub Flow promotes a simpler workflow centered around feature branches that are merged directly into the main branch upon completion. The choice of strategy depends on the project’s size, complexity, and team preferences. A clear understanding and consistent application of the chosen strategy are vital for successful collaboration.
Version Control’s Role in Maintaining Clean Code
Version control isn’t just about tracking changes; it actively supports the creation and maintenance of clean code. The ability to easily revert to previous versions allows for quick correction of errors or the removal of messy code. Furthermore, the granular history provided by version control allows developers to trace the evolution of specific code sections, making it easier to identify areas that might need refactoring or improvement. The process of reviewing code changes through pull requests or merge requests, a standard practice in most version control workflows, encourages code review and enhances code quality, directly contributing to cleaner, more maintainable code. Think of it as a built-in safety net and collaborative review process, ensuring the overall codebase remains consistent and high-quality.
Outcome Summary
Mastering clean code isn’t a destination, it’s a journey. By embracing the principles Artikeld here – from crafting descriptive variable names to implementing robust error handling – you’ll not only improve the quality of your code but also enhance your overall development workflow. Think of it as an investment in your future self (and your sanity!). So, ditch the spaghetti code, embrace clarity, and watch your productivity soar. Happy coding!



{kind=link}