Mastering Regular Expressions in JavaScript: Dive into the wild world of regex! This isn’t your grandma’s string manipulation; we’re talking about powerful pattern matching that lets you wrangle text like a pro. From basic syntax to advanced techniques, we’ll unravel the mysteries of regex and show you how to harness its power in your JavaScript projects. Get ready to become a regex ninja!
This guide walks you through the fundamentals of regular expressions, covering everything from basic metacharacters and character classes to advanced concepts like lookarounds and flags. We’ll explore practical applications in JavaScript, including form validation, data extraction, and text manipulation. We’ll even tackle debugging and troubleshooting, so you can confidently conquer any regex challenge.
Introduction to Regular Expressions in JavaScript
Regular expressions, often shortened to “regex” or “regexp,” are powerful tools for pattern matching within strings. They’re essentially mini-programming languages embedded within JavaScript (and many other programming languages), allowing you to search, replace, and manipulate text with incredible precision and efficiency. Think of them as highly specialized search-and-replace functions on steroids. Mastering them unlocks a world of possibilities for data cleaning, validation, and manipulation.
Regular expressions use a specific syntax to define patterns. These patterns can be simple, like searching for a specific word, or incredibly complex, allowing you to match intricate structures within text. The core of regex lies in its ability to define and locate these patterns within larger strings of text.
Common Regular Expression Patterns
Regular expressions utilize a set of special characters and metacharacters to define patterns. Here are a few common examples and their uses in JavaScript:
/[a-z]/g: Matches any lowercase letter (a-z). The ‘g’ flag ensures all matches are found, not just the first./\d+/g: Matches one or more digits (0-9)./\s+/g: Matches one or more whitespace characters (spaces, tabs, newlines)./\bhello\b/g: Matches the word “hello” specifically, using word boundaries (\b) to avoid matching “hello world” as “hello”./^[A-Z][a-z]+ [A-Z][a-z]+$/: Matches strings that start with a capital letter, followed by one or more lowercase letters, a space, and then another capital letter followed by one or more lowercase letters (e.g., a simple name format).
These are just a few basic examples; the possibilities are virtually limitless, allowing for incredibly nuanced pattern matching.
Benefits of Using Regular Expressions
Regular expressions offer several significant advantages for string manipulation:
- Efficiency: They provide a concise and efficient way to perform complex string operations that would be cumbersome or impossible to achieve with standard string methods alone.
- Flexibility: They allow for highly flexible pattern matching, enabling you to handle a wide variety of text formats and structures.
- Conciseness: Complex pattern matching can be expressed in a surprisingly compact way using regular expressions, improving code readability and maintainability.
- Data Validation: They are invaluable for validating user input, ensuring data conforms to specific formats (e.g., email addresses, phone numbers).
- Data Extraction: They can extract specific information from large text blocks, such as parsing log files or extracting data from HTML.
For example, imagine validating email addresses. A regex can efficiently check for the presence of “@” and a domain name, saving you from writing lengthy, error-prone custom validation functions.
Comparison of Regular Expression Engines
While JavaScript’s built-in regex engine is powerful, it’s useful to understand that different programming languages and tools might have subtle variations in their regex implementations. The differences are often minor for common use cases but can become significant when dealing with advanced features or edge cases. Here’s a simplified comparison:
| Engine | Features | Strengths | Weaknesses |
|---|---|---|---|
| JavaScript (ECMAScript) | Supports most common regex features, including flags like ‘g’ (global), ‘i’ (case-insensitive), and ‘m’ (multiline). | Widely available, well-documented, and generally performant. | Some advanced features found in other engines may be absent or implemented differently. |
| PCRE (Perl Compatible Regular Expressions) | A very powerful and widely used engine, often considered the gold standard. Supports many advanced features. | Extremely powerful and versatile, widely supported across many languages and tools. | Can be more complex to learn due to its extensive feature set. |
| Python’s re module | Similar to PCRE in power and functionality. | Well-integrated into Python’s ecosystem, extensive documentation. | Performance can be a concern for extremely large datasets. |
Note that this is a simplified comparison. The actual performance and feature sets can vary based on the specific implementation of the engine.
Basic Syntax and Metacharacters
Source: freecodecamp.org
Conquering JavaScript’s regex engine? It’s a superpower for data wrangling, but remember, even the most robust code can face unexpected pitfalls. Protecting your digital assets is key, much like securing your business with the right insurance; check out this guide on How Liability Insurance Can Protect Your Business from Lawsuits to understand risk management. Back to regex: mastering it ensures your data’s clean and your applications are rock-solid.
Regular expressions, or regexes, are powerful tools for pattern matching within strings. Understanding their basic syntax and the special metacharacters is key to unlocking their full potential in JavaScript. This section dives into the core components, providing clear explanations and practical examples to get you regex-ready.
Regular expressions are essentially mini-languages built for pattern searching. They use a combination of literal characters and special metacharacters to define what you’re looking for. Mastering these building blocks will enable you to create sophisticated expressions for various tasks, from data validation to text manipulation.
Literal Characters
Literal characters are simply the characters you want to match exactly. For example, the regex “hello” will only match the string “hello”. No special interpretation is applied; it’s a direct character-by-character comparison. This forms the foundation upon which you build more complex patterns using metacharacters.
Metacharacters
Metacharacters are special characters that have a specific meaning within a regular expression. They allow you to create flexible and powerful patterns that can match a wider range of strings than simple literal character matches.
Here’s a breakdown of common metacharacters and their functionalities, along with illustrative examples:
- . (Dot): Matches any single character (except newline). Example:
/h.llo/matches “hello”, “hallo”, “h3llo”, etc. - * (Asterisk): Matches the preceding element zero or more times. Example:
/ab*c/matches “ac”, “abc”, “abbc”, “abbbc”, etc. - + (Plus): Matches the preceding element one or more times. Example:
/ab+c/matches “abc”, “abbc”, “abbbc”, etc., but not “ac”. - ? (Question Mark): Matches the preceding element zero or one time. Example:
/colou?r/matches both “color” and “colour”. - ^ (Caret): Matches the beginning of a string. Example:
/^Hello/matches “Hello world” but not “World Hello”. - $ (Dollar Sign): Matches the end of a string. Example:
/world$/matches “Hello world” but not “Hello world!”. - \ (Backslash): Escapes special characters or creates special character sequences. Example:
/\./matches a literal dot,/\d/matches a digit. - [] (Square Brackets): Defines a character set. Example:
/[abc]/matches “a”, “b”, or “c”./[a-z]/matches any lowercase letter. - (Curly Braces): Specifies the number of repetitions. Example:
/a2,4b/matches “aab”, “aaab”, “aaaab”, but not “ab” or “aaaaab”. - | (Pipe): Acts as an “or” operator. Example:
/cat|dog/matches “cat” or “dog”. - () (Parentheses): Creates capturing groups. Example:
/(abc)/captures “abc” as a group. This is useful for extracting parts of a matched string.
These metacharacters, combined with literal characters, allow you to create highly specific and flexible patterns to match virtually any text pattern you can imagine. Remember to experiment and practice – the best way to master regex is by doing!
Character Classes and Quantifiers: Mastering Regular Expressions In JavaScript
Regular expressions, those mystical strings that let you search and manipulate text like a digital sorcerer, get even more powerful when you add character classes and quantifiers to your arsenal. Think of them as the secret ingredients that transform basic pattern matching into finely-tuned text wrangling. This section will unravel their mysteries and show you how to use them to tame even the wildest text.
Character classes define sets of characters you want to match, while quantifiers specify how many times a character or group should appear. Mastering these two concepts is key to writing efficient and accurate regular expressions.
Character Classes
Character classes allow you to specify a range of characters you wish to match within a single expression. This significantly enhances the flexibility and efficiency of your regex. Instead of listing every single character individually, you can define sets. For example, if you need to match any lowercase letter, using `[a-z]` is much more concise than `a|b|c|d…|z`.
Here are some commonly used character classes:
- [a-z]: Matches any lowercase letter from ‘a’ to ‘z’.
- [A-Z]: Matches any uppercase letter from ‘A’ to ‘Z’.
- [0-9]: Matches any digit from 0 to 9. This is often shortened to \d.
- \d: A shorthand for [0-9], matching any digit.
- \D: Matches any character that is *not* a digit (opposite of \d).
- [a-zA-Z0-9]: Matches any alphanumeric character (lowercase, uppercase, or digit).
- \w: A shorthand for [a-zA-Z0-9_], matching any alphanumeric character or underscore.
- \W: Matches any character that is *not* an alphanumeric character or underscore (opposite of \w).
- . (dot): Matches any character except a newline character.
- \s: Matches any whitespace character (space, tab, newline, etc.).
- \S: Matches any character that is *not* a whitespace character (opposite of \s).
Let’s say you want to extract all email addresses from a text. A simplified regex might use `[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]2,`. This leverages character classes to efficiently define the allowed characters in the username and domain parts of an email.
Quantifiers, Mastering Regular Expressions in JavaScript
Quantifiers determine how many times a preceding element (a character, a character class, or a group) must appear to satisfy the match. They add a powerful layer of control to your regex.
Here’s a breakdown of the most common quantifiers:
- *: Matches zero or more occurrences of the preceding element. For example, `colou?r` matches both “color” and “colour”.
- +: Matches one or more occurrences of the preceding element. For example, `ab+c` matches “abc”, “abbc”, “abbbc”, etc., but not “ac”.
- ?: Matches zero or one occurrence of the preceding element. For example, `colou?r` matches both “color” and “colour”.
- n: Matches exactly n occurrences of the preceding element. For example, `a3` matches “aaa”.
- n,: Matches n or more occurrences of the preceding element. For example, `a2,` matches “aa”, “aaa”, “aaaa”, etc.
- n,m: Matches at least n and at most m occurrences of the preceding element. For example, `a2,4` matches “aa”, “aaa”, and “aaaa”.
Consider extracting phone numbers. A simple regex like `\d3-\d3-\d4` specifically targets numbers in the format XXX-XXX-XXXX. The `3` and `4` quantifiers ensure the correct number of digits in each part.
Combining Character Classes and Quantifiers
The real magic happens when you combine character classes and quantifiers. This allows you to create incredibly flexible and powerful patterns.
Let’s look at an example. Suppose you want to find all words that start with a capital letter and are followed by two or more lowercase letters. The regex `[A-Z][a-z]2,` would perfectly capture this. `[A-Z]` matches the initial capital letter, and `[a-z]2,` ensures at least two lowercase letters follow.
Another example: Imagine you need to validate a password that must contain at least eight characters, including at least one uppercase letter, one lowercase letter, and one digit. While a complete solution requires lookaheads (a more advanced regex feature), we can start building it using character classes and quantifiers: `^(?=.*[A-Z])(?=.*[a-z])(?=.*\d).8,$` (Note: this uses lookaheads, which are beyond the scope of this section, but illustrates the power of combining concepts). This uses quantifiers to specify minimum length and character classes to specify required character types.
Anchors and Boundaries
Regular expressions are all about pattern matching, but sometimes you need more control over *where* that pattern appears within a string. That’s where anchors and boundaries come in – they’re like special markers that tell your regex engine to only match patterns at specific positions within the text. Think of them as precision tools for your regex arsenal.
Anchors and boundaries are essential for ensuring your regex matches exactly what you intend, avoiding unintended matches elsewhere in the string. Mastering these concepts will significantly improve the accuracy and efficiency of your regular expressions.
Caret and Dollar Sign Anchors
The caret (^) and dollar sign ($) are the most fundamental anchors. The caret matches the beginning of a string, while the dollar sign matches the end. This allows you to create regexes that only match patterns that appear at the very start or very end of your input text. Using them prevents accidental matches that occur in the middle of a string. For example, `^Hello` will only match “Hello” if it’s at the beginning of the string, and `World$` will only match “World” if it’s at the end.
Word Boundaries
The word boundary metacharacter, `\b`, matches the position between a word character (\w) and a non-word character (\W), or between a word character and the beginning or end of a string. It’s incredibly useful for finding whole words without accidentally matching parts of other words. For example, `\bcat\b` will match “cat” but not “scat” or “tomcat”. This precision is critical when you need to isolate specific words from a larger text.
Examples: Anchors in Action
Let’s illustrate the difference between using and not using anchors with some concrete examples.
- Scenario: Find all instances of “apple” in a string.
Without anchors: The regex
applewill match “apple” wherever it appears – in the middle, beginning, or end of a string. For example, in the string “pineapple apple pie”, it would match both instances.With anchors:
^applewould only match “apple” if it’s at the beginning of the string, whileapple$would only match it if it’s at the end. - Scenario: Find the word “JavaScript” in a sentence.
Without word boundaries: The regex
JavaScriptmight accidentally match “JavaScripting” or “PostJavaScript”.With word boundaries: The regex
\bJavaScript\bwill precisely match only the word “JavaScript”, avoiding partial matches. - Scenario: Extract phone numbers in the format XXX-XXX-XXXX from a text.
Without anchors: A regex like
\d3-\d3-\d4might match a substring within a longer number.With anchors (and word boundaries):
\b\d3-\d3-\d4\bwill help ensure that only complete phone numbers are matched, preventing false positives. However, this may not cover all possible phone number formats, a more robust regex might be needed for production.
Grouping and Capturing
Regular expressions often need to do more than just find a match; they need to dissect it. This is where grouping and capturing come in, allowing you to isolate and extract specific parts of a matched string. Think of it as surgically precise string manipulation – you pinpoint exactly what you want and pull it out. It’s like having a tiny, highly trained regex ninja extracting information from a chaotic text jungle.
Grouping uses parentheses `()` to create subgroups within a regular expression. These groups serve two main purposes: they allow you to apply quantifiers or other operators to a whole section of the regex, and they enable capturing of specific matched substrings for later use.
Capturing Groups for Extracting Substrings
Capturing groups are essentially parentheses that save the matched text within them. Each capturing group is assigned a number, starting from 1, based on its position in the regex. You can then access these captured groups using the appropriate methods provided by your programming language (in this case, JavaScript). For example, the regex `(apple)(banana)` has two capturing groups: one capturing “apple” and the other capturing “banana”.
Let’s say you have the string “My favorite fruits are apple and banana.” and you want to extract the fruits. The regex `(apple|banana)` would only find one fruit at a time. Using capturing groups, we can create a regex that will extract both. The regex `(apple) and (banana)` would allow you to extract both “apple” and “banana” into separate captured groups. JavaScript’s `exec()` or `match()` methods will return an array where the captured groups are accessible at indices 1, 2, and so on (index 0 usually contains the whole match).
Practical Applications of Capturing Groups
Capturing groups are invaluable in many real-world scenarios:
* Data parsing: Extracting names, dates, email addresses, or other structured information from unstructured text. For example, parsing a log file to extract error codes and timestamps.
* Data transformation: Modifying parts of a string based on captured groups. For instance, converting date formats or standardizing text.
* Web scraping: Pulling specific data from web pages. Imagine extracting product names and prices from an e-commerce website.
Examples of Capturing Groups in Use
Let’s illustrate with a table:
| Example | Regex | Captured Groups | Explanation |
|---|---|---|---|
| “My email is [email protected]” | (\w+)@(\w+)\.(\w+) | test, example, com | Captures the username, domain, and top-level domain of an email address. |
| “The date is 2024-10-26” | (\d4)-(\d2)-(\d2) | 2024, 10, 26 | Captures the year, month, and day from a date string. |
| “Order #12345, total $99.99” | Order #(\d+), total \$([\d.]+) | 12345, 99.99 | Captures the order number and the total amount. Note the escaping of special characters like ‘$’ and ‘.’ |
| “John Doe ([email protected])” | (.+?) \((.+?)\) | John Doe, [email protected] | Captures the name and the email address, using non-greedy quantifiers to avoid capturing too much. |
Advanced Techniques
Level up your JavaScript regex game with advanced techniques! We’ve covered the basics, but mastering regular expressions truly unlocks their power. This section dives into lookarounds – a powerful tool for conditional matching – and explores the various flags that significantly alter regex behavior. Get ready to write more precise and efficient expressions.
Lookarounds: Assertions, Not Consumption
Lookarounds are zero-width assertions; they check for a pattern’s presence or absence without actually including it in the match. This allows for incredibly nuanced matching. Positive lookaheads (`(?=pattern)`) assert that the pattern *follows* the current position, while negative lookaheads (`(?!pattern)`) assert that the pattern *does not* follow. Positive lookbehinds (`(?<=pattern)`) assert that the pattern *precedes* the current position, and negative lookbehinds (`(?Lookahead Examples
Let’s illustrate with examples. Suppose we want to find all occurrences of “apple” that are followed by “pie”:
/apple(?=pie)/g
This regex will only match “apple” if “pie” immediately follows. “apple pie” will match, but “apple sauce” will not. To find all occurrences of “apple” that are *not* followed by “pie”, we use a negative lookahead:
/apple(?!pie)/g
Now, “apple sauce” will match, but “apple pie” will not.
Lookbehind Examples
For lookbehinds (where supported), imagine finding all instances of “pie” that are preceded by “apple”:
/(?<=apple)pie/g
Only "apple pie" would match. A negative lookbehind to find "pie" not preceded by "apple" would be:
/(?
This would match "cherry pie" but not "apple pie". Remember that lookbehind support varies across JavaScript environments.
Regex Flags: Modifying the Matching Behavior
Regex flags modify how the regex engine performs matching. The most common flags are:
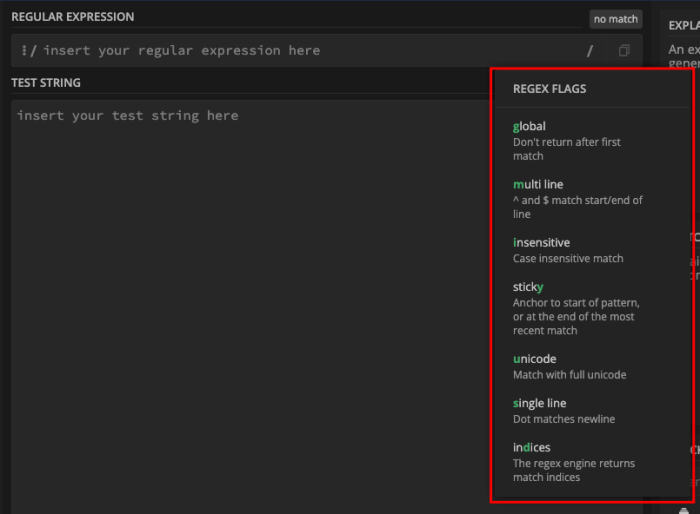
g(global): Finds all matches in the string, not just the first.i(case-insensitive): Matches both uppercase and lowercase letters.m(multiline): Allows `^` and `$` to match the beginning and end of each line, respectively, in multiline strings.
These flags are appended after the closing `/` of the regex literal. For example, `/apple/gi` would find all occurrences of "apple", regardless of case.
Complex Regex Example: Email Validation (Illustrative)
Let's craft a robust, albeit simplified, email validation regex using lookarounds and flags:
/^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]2,$/
This regex, while not perfect for all edge cases, demonstrates the power of combining techniques. It checks for:
* One or more alphanumeric characters, periods, underscores, percentage signs, plus or minus signs at the beginning (`^[a-zA-Z0-9._%+-]+`).
* An "@" symbol.
* One or more alphanumeric characters, periods, or hyphens.
* A period (`.`).
* Two or more alphabetic characters at the end (`[a-zA-Z]2,$`).
While this provides a basic framework, a truly comprehensive email validation regex would be significantly more complex, handling various edge cases and internationalized domain names. This example highlights how combining basic elements with lookarounds and flags allows for more sophisticated pattern matching.
Practical Applications in JavaScript

Source: attacomsian.com
Regular expressions, or regex, aren't just theoretical concepts; they're powerful tools that significantly streamline JavaScript development. Mastering them unlocks efficient solutions for a wide range of tasks, from validating user input to extracting data from complex strings. Let's dive into some practical applications showcasing the versatility of regex in JavaScript.
Using String Methods: match(), replace(), and test()
JavaScript provides built-in string methods that seamlessly integrate with regular expressions. `String.prototype.match()` finds all matches of a pattern within a string, returning an array. `String.prototype.replace()` substitutes matched substrings with a new string, offering powerful text manipulation capabilities. Finally, `String.prototype.test()` checks if a pattern exists within a string, returning a simple boolean value. These methods form the core of many regex-based solutions.
For example, let's say we have the string "My email is [email protected] and another is [email protected]". Using /[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]2,/g.match(myString) would return an array containing "[email protected]" and "[email protected]". Replacing "example" with "newExample" using myString.replace(/example/g, "newExample") would change the string to "My email is [email protected] and another is [email protected]". And /[a-z]/.test("Hello") would return true because the string contains a lowercase letter.
Form Validation with Regular Expressions
Regex shines in form validation. Instead of cumbersome manual checks, you can use concise regex patterns to ensure data conforms to specific formats. This enhances user experience by providing immediate feedback and preventing invalid data from reaching your server.
Consider validating an email address. A regex like /^[\w-\.]+@([\w-]+\.)+[\w-]2,4$/ provides a robust check for valid email structures. You can integrate this directly into your JavaScript form validation, ensuring only correctly formatted email addresses are accepted. Similarly, validating phone numbers, postal codes, or dates becomes significantly easier with the appropriate regex patterns. For example, a simple phone number validation could use /^\(?\d3\)?[-.\s]?\d3[-.\s]?\d4$/ to check for a common North American phone number format.
Data Extraction from Text
Extracting specific information from large text bodies is a common task. Regular expressions simplify this process by allowing you to pinpoint and isolate relevant data efficiently.
Imagine you're parsing a log file to find all error messages. A regex pattern targeting error codes or specific s can quickly extract those messages for analysis. For instance, a pattern like /Error:.*?\n/g might extract lines containing "Error:" followed by the error message up to the next newline character. This is significantly more efficient than manually iterating through each line and checking for error messages.
Text Manipulation and Cleaning
Regular expressions excel at cleaning and manipulating text. Tasks like removing extra whitespace, standardizing formats, or replacing specific characters are easily handled with regex.
For example, removing extra spaces from a string can be achieved using /\s+/g and replacing them with a single space. Converting text to lowercase or uppercase is straightforward with methods like .toLowerCase() and .toUpperCase(). Regular expressions provide the precision to target specific elements for modification, avoiding unintended changes to the text. Consider cleaning a string of HTML tags with /<[^>]+>/g and replacing it with an empty string.
Debugging and Troubleshooting
Regular expressions, while incredibly powerful, can be notoriously tricky to debug. A misplaced character or a misunderstood metacharacter can lead to hours of frustration. This section dives into common pitfalls and provides strategies to tame even the wildest regex beasts. We'll cover identifying common errors, effective debugging techniques, and best practices for writing clean, maintainable regex code.
Common Regex Mistakes
Many common mistakes stem from a misunderstanding of how regex engines interpret patterns. For example, forgetting to escape special characters within character classes can lead to unexpected results. Similarly, incorrect quantifier usage or neglecting to account for edge cases (like empty strings or whitespace) are frequent sources of errors. Another common problem is the overuse of overly complex patterns. A simpler, more modular approach is often more effective and easier to debug.
Strategies for Debugging Complex Regex Patterns
Debugging complex regex patterns requires a systematic approach. Start by breaking down the pattern into smaller, more manageable chunks. Test each component individually to isolate the source of any errors. Using a regex testing tool with visualization capabilities (many online tools exist) can be incredibly helpful. These tools allow you to step through the matching process, highlighting which parts of the string are matched by each part of the regex. For example, you might use a tool to see exactly where a quantifier is failing or why a character class isn't matching as expected. Commenting your regex, especially for complex parts, can dramatically improve readability and help during debugging.
Improving Readability and Maintainability
Readability is key to maintainable regex code. Use descriptive variable names if you're storing regex patterns in variables. Employ whitespace consistently within your patterns to improve visual clarity. Avoid overly long or nested patterns. Instead, break them down into smaller, reusable components. Consider using comments to explain complex parts of your regex. For instance, if you have a particularly intricate character class, a comment explaining its purpose can be invaluable.
Remember: A well-structured regex is easier to read, debug, and maintain than a sprawling, uncommented mess. Prioritize clarity over cleverness. A slightly longer, but easily understandable, regex is far preferable to a concise but cryptic one.
Final Review

Source: medium.com
So, you've conquered the regex beast! You're now equipped with the skills to efficiently manipulate strings, validate user input, and extract data with precision. Remember, practice makes perfect – keep experimenting, and soon you’ll be effortlessly wielding the power of regular expressions in all your JavaScript endeavors. Happy coding!



{kind=link}