A Guide to Understanding Recursion in Computer Science: Dive into the fascinating world of recursive functions! Think of it like a set of Russian nesting dolls—each doll contains a smaller version of itself, until you reach the tiniest one. Recursion in programming works similarly, breaking down complex problems into smaller, self-similar subproblems until a simple solution is found. This guide unravels the mysteries of base cases, recursive steps, and common algorithms, showing you how recursion elegantly solves problems in computer science.
We’ll explore its applications in data structures like trees and graphs, comparing its strengths and weaknesses against iterative approaches. We’ll even tackle debugging and optimization techniques, ensuring you can wield this powerful tool effectively. Get ready to unlock the power of recursion and elevate your coding game!
Introduction to Recursion
Recursion, in the realm of computer science, is a powerful technique where a function calls itself within its own definition. It’s a bit like a set of Russian nesting dolls, each doll containing a smaller version of itself, until you reach the smallest doll. This self-referential approach allows for elegant solutions to problems that can be broken down into smaller, self-similar subproblems. Understanding recursion unlocks the ability to solve complex challenges with surprisingly concise code.
Recursion is a problem-solving approach where a function solves a problem by calling a smaller version of itself. Imagine you’re organizing a large stack of papers. You might decide to tackle it recursively: first, divide the stack in half. Then, recursively apply the same process to each half-stack, continuing until you have individual papers. This is analogous to a recursive function breaking down a large problem into smaller, identical subproblems until a simple base case is reached, which can be solved directly.
Recursive Function Definition and Characteristics
Recursion involves a function calling itself, directly or indirectly. This self-call continues until a base case is reached – a condition that stops the recursive calls and allows the function to begin returning values up the call stack. Key characteristics include the base case, which prevents infinite recursion, and the recursive step, where the function calls itself with a modified input, moving closer to the base case. Without a properly defined base case, the function will call itself endlessly, leading to a stack overflow error.
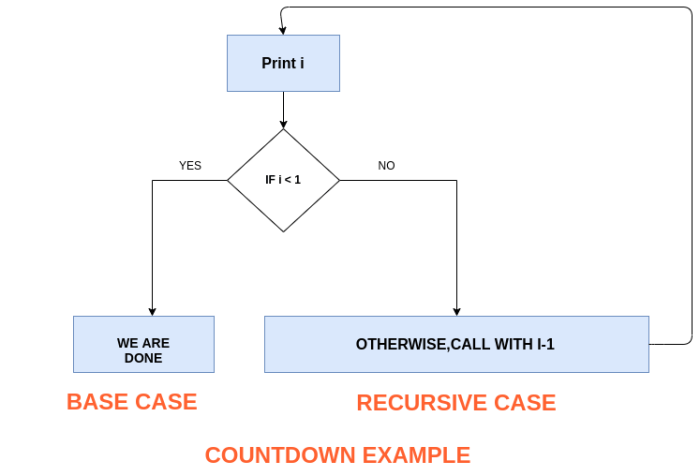
Flowchart of a Recursive Function Call
A flowchart illustrating a recursive function call would visually represent the repeated self-calls. Imagine a box representing the function. Inside this box, there’s a decision point: Is the base case met? If yes, a path leads to a “return value” box, indicating the function’s result. If no, a path leads back to the same function box, but with modified input parameters, representing the recursive call. Arrows show the flow of execution, demonstrating the repeated calls until the base case is reached, after which the function unwinds, returning values at each step back to the initial call. This visual representation clearly depicts the iterative nature of the recursive process and the crucial role of the base case in halting the recursion.
Base Cases and Recursive Steps

Source: slidetodoc.com
Recursion, that mind-bending technique where a function calls itself, isn’t magic; it’s a carefully orchestrated dance between two key players: the base case and the recursive step. Understanding their roles is crucial to writing elegant and, more importantly, *functional* recursive code. Without them, you’re heading straight for a stack overflow – a digital equivalent of a never-ending loop of mirrors.
Think of it like Russian nesting dolls: each doll contains a smaller, self-similar version until you reach the smallest doll – the base case. This smallest doll stops the nesting; it’s the termination condition. The recursive step, on the other hand, is the process of opening a doll to reveal the next smaller one. It’s the mechanism that breaks the problem into smaller, manageable pieces.
The Role of the Base Case in Preventing Infinite Recursion
The base case is the unsung hero of recursion. It’s the condition that stops the function from calling itself indefinitely. Without a well-defined base case, the function would continue to call itself, consuming ever more memory until your program crashes. Imagine a recursive function that never reaches its base case – it’s like a never-ending story, except instead of a captivating tale, you get a program crash. The base case acts as the escape hatch, ensuring the function eventually completes its execution. It’s the “if this condition is met, stop calling myself” instruction. A simple example is a factorial function; the base case is when the input (n) reaches 0, because the factorial of 0 is 1.
Breaking Down Problems into Smaller, Self-Similar Subproblems
Recursion excels at tackling problems that can be broken down into smaller, self-similar subproblems. This “divide and conquer” strategy is the heart of recursion. For instance, calculating the factorial of 5 (5!) can be broken down into 5 * 4!, then 4! into 4 * 3!, and so on, until you reach the base case of 0!. Each subproblem is essentially the same problem, just on a smaller scale. This self-similarity is what makes recursion so powerful and, at times, elegantly concise.
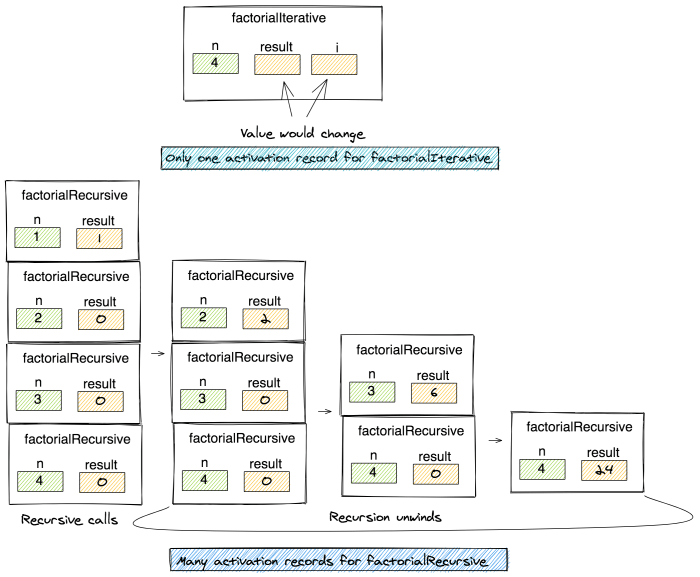
Comparison of Iterative and Recursive Approaches to Solving the Factorial Problem
The factorial problem provides a perfect illustration of the differences between iterative and recursive approaches. Both achieve the same result – calculating the factorial – but they do so in fundamentally different ways.
| Method | Approach | Code Example (Python) | Advantages |
|---|---|---|---|
| Iterative | Uses a loop to repeatedly multiply numbers. | def factorial_iterative(n): |
Generally more efficient in terms of memory usage and speed, especially for larger numbers. Easier to understand for beginners. |
| Recursive | Defines the factorial in terms of itself, using a base case to stop the recursion. | def factorial_recursive(n): |
Often leads to more concise and elegant code, reflecting the mathematical definition of the factorial more directly. |
Common Recursive Algorithms
Source: medium.com
Recursion, that elegant dance of self-reference in programming, finds practical application in solving a surprisingly wide range of problems. Mastering recursive algorithms unlocks a powerful tool for tackling complex tasks with often surprisingly concise code. Let’s delve into some common examples, exploring their implementation, efficiency, and the different flavors of recursion they employ.
Factorial Calculation
The factorial of a non-negative integer n, denoted by n!, is the product of all positive integers less than or equal to n. This classic example perfectly illustrates the essence of recursion. The base case is when n equals 0, where the factorial is defined as 1. The recursive step involves multiplying n by the factorial of (n-1).
- Base Case: If n = 0, return 1.
- Recursive Step: If n > 0, return n * factorial(n-1).
A simple Python implementation would look like this:
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n - 1)
Iteratively, we’d use a loop, accumulating the product. While both approaches achieve the same result, the recursive version is arguably more elegant, directly mirroring the mathematical definition. However, for very large numbers, the recursive approach can lead to stack overflow errors due to excessive function calls, whereas the iterative method is generally more efficient in terms of space complexity (O(1) vs O(n) for the recursive approach).
Fibonacci Sequence Generation
The Fibonacci sequence, where each number is the sum of the two preceding ones (starting with 0 and 1), is another excellent demonstration of recursion. The base cases are the first two numbers in the sequence. The recursive step calculates the next number by summing the previous two.
- Base Cases: If n = 0, return 0; if n = 1, return 1.
- Recursive Step: If n > 1, return fibonacci(n-1) + fibonacci(n-2).
Python implementation:
def fibonacci(n):
if n <= 1: return n else: return fibonacci(n-1) + fibonacci(n-2)
Similar to the factorial example, the recursive Fibonacci solution is conceptually clear but suffers from significant performance issues for larger values of n due to repeated calculations. An iterative solution offers a much-improved time complexity (O(n) vs O(2n) for the naive recursive approach).
Tower of Hanoi
The Tower of Hanoi puzzle, involving moving a stack of disks from one peg to another with certain constraints, provides a compelling example of a more complex recursive algorithm. The base case is when there's only one disk, which is trivially moved. The recursive step involves moving n-1 disks to an auxiliary peg, moving the largest disk to the target peg, and then moving the n-1 disks from the auxiliary peg to the target peg.
- Base Case: If n = 1, move the disk from source to destination.
- Recursive Step: Move n-1 disks from source to auxiliary, move the largest disk from source to destination, move n-1 disks from auxiliary to destination.
While a detailed Python implementation is beyond the scope of this brief overview, the recursive nature of the solution is evident in its breakdown into smaller, self-similar subproblems. The time complexity of the recursive Tower of Hanoi solution is O(2n), reflecting the exponential growth in the number of moves required as the number of disks increases. An iterative solution exists, but it's significantly more complex to implement.
Recursion in Data Structures
Source: googleapis.com
Recursion finds its true power when applied to data structures that inherently exhibit a self-similar, hierarchical nature, like trees and graphs. These structures lend themselves beautifully to recursive solutions because their organization mirrors the recursive function's call structure. Understanding how recursion interacts with these data types is key to writing elegant and efficient algorithms.
Recursive Tree Traversal
Tree traversal involves visiting each node in a tree exactly once. Recursive algorithms provide a concise and intuitive way to accomplish this. Binary trees, and their more specialized cousin the binary search tree, are prime examples where recursive traversal shines. The core idea is to recursively explore the left and right subtrees, ensuring that each node is visited in a specific order.
Implementing Recursive Tree Traversal Algorithms
Preorder, inorder, and postorder traversals are the three primary ways to recursively traverse a binary tree. In preorder traversal, the current node is visited first, followed by a recursive call to the left subtree, and finally, a recursive call to the right subtree. Inorder traversal visits the left subtree recursively, then the current node, and finally the right subtree recursively. Postorder traversal reverses this order, recursively visiting the left and right subtrees before visiting the current node. The choice of traversal depends on the specific application; for instance, inorder traversal is crucial for maintaining the sorted order in a binary search tree.
Recursive Graph Traversal: Depth-First Search
Graphs, unlike trees, can have cycles and multiple paths between nodes. Depth-first search (DFS) is a graph traversal algorithm that uses recursion to explore as far as possible along each branch before backtracking. It starts at a root node and recursively explores each unvisited neighbor. This process continues until all reachable nodes are visited. The recursive nature allows DFS to naturally follow paths deeply into the graph. The algorithm maintains a visited set to avoid revisiting nodes and infinite loops caused by cycles.
Visual Representation of Binary Tree Traversal
Let's consider a binary tree with the root node 'A', left child 'B', and right child 'C'. 'B' has a left child 'D' and a right child 'E', while 'C' has only a left child 'F'. Let's visualize a preorder traversal.
1. Start at the root (A): Visit A.
2. Recursively traverse the left subtree (B): Visit B.
3. Recursively traverse the left subtree of B (D): Visit D.
4. Recursively traverse the right subtree of B (E): Visit E.
5. Recursively traverse the right subtree (C): Visit C.
6. Recursively traverse the left subtree of C (F): Visit F.
The preorder traversal sequence would be A, B, D, E, C, F. Inorder traversal would yield D, B, E, A, F, C, and postorder would give D, E, B, F, C, A. This demonstrates how the order of recursive calls directly impacts the traversal sequence. The recursive nature simplifies the process of visiting each node systematically. The same principles apply to more complex tree structures.
Advantages and Disadvantages of Recursion
Recursion, that elegant dance of self-referential functions, offers a powerful tool for solving certain problems in computer science. However, like any powerful tool, it comes with its own set of strengths and weaknesses. Understanding these is crucial for choosing the right approach when crafting your code. This section will delve into the advantages and disadvantages of using recursion, helping you make informed decisions in your programming endeavors.
Advantages of Recursion
The beauty of recursion often lies in its ability to express complex algorithms concisely and elegantly. This readability can significantly improve code maintainability and understanding, especially for problems naturally represented recursively, such as tree traversal or fractal generation. Let's examine the key benefits:
- Enhanced Code Readability: Recursive solutions can often be more intuitive and easier to understand than their iterative counterparts, particularly for problems that exhibit a self-similar structure. For example, calculating a factorial using recursion directly reflects the mathematical definition, making the code more self-.
- Simplified Problem Solving: Certain problems, like traversing hierarchical data structures (trees, graphs), are inherently recursive. A recursive approach directly mirrors the problem's structure, leading to simpler and more elegant solutions.
- Reduced Code Complexity: In some cases, a recursive solution can be shorter and easier to implement than an iterative one, leading to less code and fewer potential errors.
Disadvantages of Recursion
While recursion offers elegance, it's not without its drawbacks. These limitations are important to consider before opting for a recursive approach.
- Stack Overflow Errors: Each recursive call adds a new frame to the call stack. Deep or excessively recursive functions can exhaust the available stack space, leading to a stack overflow error and program crash. This is particularly problematic when dealing with large input sizes or poorly designed recursive functions lacking proper base cases.
- Higher Space Complexity: Recursion generally consumes more memory than iteration due to the overhead of managing the call stack. Each recursive call requires storing function parameters, local variables, and return addresses on the stack. This can be significant for deeply recursive functions.
- Slower Execution Speed: The function call overhead associated with recursion can lead to slower execution compared to iterative solutions. The repeated function calls and stack management add computational overhead.
Scenarios Favoring Recursion or Iteration
The choice between recursion and iteration often depends on the specific problem and its characteristics.
Recursion is often preferred for problems that naturally exhibit a self-similar structure, such as tree traversal, quicksort, and the Tower of Hanoi. The recursive solution directly mirrors the problem's inherent structure, resulting in clear, concise code. However, for problems involving large datasets or where stack overflow is a concern, an iterative approach is usually more efficient and safer. For example, calculating the factorial of a very large number would be significantly more efficient iteratively.
Wrestling with the mind-bending concept of recursion in computer science? It's like a digital hall of mirrors, but understanding it unlocks powerful programming techniques. Think of it as a layered defense, much like securing your small business from cyber threats – something you can learn more about by checking out this guide on How to Protect Your Small Business from Cyber Attacks with Insurance.
Mastering recursion is similarly about building robust, layered solutions to complex problems.
Iteration, on the other hand, is generally preferred for problems where performance is critical or where the depth of recursion might be unpredictable. Iterative solutions have lower memory overhead and typically execute faster, making them suitable for performance-sensitive applications. Simple repetitive tasks are often best handled iteratively.
Debugging and Optimizing Recursive Functions
Recursive functions, while elegant and powerful, can be tricky to debug and optimize. Their inherent nested structure can make it difficult to track the flow of execution and identify the source of errors. Efficiently managing recursion requires a blend of systematic debugging techniques and strategic optimization strategies. This section explores common pitfalls and effective solutions to ensure your recursive functions are both correct and performant.
Debugging recursive functions often involves a different approach than debugging iterative functions. The nested nature of recursive calls necessitates a deeper understanding of the call stack and the progression of each recursive step. Simple print statements can be surprisingly effective, but more sophisticated tools are available for complex scenarios.
Tracing Function Calls
Tracing function calls is crucial for understanding the execution path of a recursive function. This involves strategically placing print statements (or using a debugger) to monitor the values of variables at each level of recursion. For example, adding print statements that show the input parameters and the return value at the beginning and end of the function can reveal the flow of data through the recursive calls. This allows you to visually track the values as they change with each recursive step, helping to pinpoint the exact point where an error occurs. Consider a factorial function: If you add print statements showing the input `n` and the calculated `n!` at each call, you can easily see if the function is correctly calculating factorials for each input.
Identifying Infinite Recursion
Infinite recursion occurs when a recursive function never reaches its base case, leading to a stack overflow error. This is a common problem in recursive programming. The key to avoiding infinite recursion is to ensure that each recursive call moves closer to the base case. Carefully examine your base case condition. Is it correctly defined? Does your recursive step guarantee that the input eventually satisfies the base case? If not, the function will call itself indefinitely. For instance, if a recursive function designed to find a value in a sorted array doesn't correctly handle the case where the value is not present, it might continue searching beyond the array bounds, resulting in infinite recursion.
Stack Overflow Exceptions
Stack overflow exceptions are a direct consequence of infinite recursion or excessively deep recursion. Each recursive call adds a new frame to the call stack. If the recursion is too deep, the stack can overflow, causing the program to crash. To prevent this, you can either: (1) Ensure your base case is correctly defined and reachable, (2) Implement iterative solutions for very large inputs, (3) increase the stack size (though this is generally not recommended as a primary solution), or (4) use techniques like tail-call optimization (discussed below).
Memoization
Memoization is an optimization technique that stores the results of expensive function calls and reuses them when the same inputs occur again. This is particularly effective for recursive functions that repeatedly compute the same values. Consider the Fibonacci sequence calculation. A naive recursive implementation recalculates many Fibonacci numbers multiple times. Memoization can dramatically improve performance by storing previously computed Fibonacci numbers and retrieving them from memory when needed, avoiding redundant calculations. This reduces the number of recursive calls and improves efficiency significantly.
Tail-Call Optimization
Tail-call optimization is a compiler optimization technique that transforms tail-recursive functions into iterative loops. A tail-recursive function is one where the recursive call is the very last operation performed. If the compiler supports tail-call optimization, it can avoid adding new frames to the call stack for each recursive call, preventing stack overflow errors even with very deep recursion. Not all programming languages or compilers support this optimization, however.
Best Practices for Writing Efficient Recursive Functions
Writing efficient and maintainable recursive functions requires careful consideration of several factors. Following these best practices can greatly improve code quality and performance.
- Clearly define the base case(s): The base case(s) must be unambiguous and easily identifiable. It determines when the recursion stops.
- Ensure the recursive step moves closer to the base case: Each recursive call should make progress toward satisfying the base case condition.
- Avoid unnecessary recursion: Consider if an iterative approach might be more efficient for certain problems.
- Use memoization where applicable: Memoization can significantly improve the performance of recursive functions that repeatedly calculate the same values.
- Consider tail-call optimization: If your programming language and compiler support it, utilize tail-call optimization to prevent stack overflow errors.
- Thoroughly test your function: Test with various inputs, including edge cases and boundary conditions, to ensure correctness.
Real-World Applications of Recursion
Recursion, that elegant dance of self-referential functions, isn't just a theoretical concept confined to computer science textbooks. It's a powerful tool with surprisingly widespread real-world applications, underpinning many of the technologies we use daily. Let's delve into some compelling examples where recursion elegantly solves complex problems.
Recursion's power lies in its ability to break down large, complex problems into smaller, self-similar subproblems. This "divide and conquer" approach makes it ideal for situations where a problem can be recursively defined – where the solution to a problem depends on solutions to smaller instances of the same problem.
Compiler Design
Compilers, the unsung heroes translating human-readable code into machine-executable instructions, heavily rely on recursion. Consider the process of parsing a program's syntax. A compiler often uses recursive descent parsing, a technique where a grammar rule is represented by a recursive function. This function calls itself to process nested structures like function calls or nested loops. For example, a function parsing arithmetic expressions might recursively handle nested parentheses: `(1 + (2 * 3))`. The parser starts with the outermost parentheses, recursively calling itself to parse the inner expression `(2 * 3)` before finally evaluating the entire expression. This recursive approach neatly handles the hierarchical nature of programming languages, ensuring accurate and efficient translation. The elegance lies in how the same parsing logic applies at each level of nesting, simplifying the overall design.
Operating System File Systems, A Guide to Understanding Recursion in Computer Science
Navigating file systems, those hierarchical structures organizing our digital world, often employs recursive algorithms. Consider the task of searching for a specific file within a directory. A recursive function can traverse the directory structure: it checks the current directory for the file, and if not found, recursively calls itself for each subdirectory. This recursive descent continues until the file is found or all subdirectories have been explored. This is a highly efficient method for searching large, complex file systems, as it systematically explores every possible location without requiring complex iterative bookkeeping. The simplicity of the recursive approach contrasts with the potential complexity of managing state in an iterative equivalent.
Artificial Intelligence: Tree Traversal Algorithms
Many algorithms in artificial intelligence, particularly those involving tree-like structures, leverage recursion extensively. Consider decision trees used in machine learning for classification. Traversing such a tree to make a prediction involves recursively moving down the tree based on feature values. Each node represents a decision, and the algorithm recursively calls itself to navigate to the appropriate child node based on the input data. This recursive traversal continues until a leaf node is reached, which provides the classification prediction. Similar recursive traversals are used in game-playing AI, such as those used in chess or Go, where the game tree represents possible game states and recursive algorithms explore potential moves and countermoves. The recursive nature efficiently handles the branching structure of these trees, enabling complex decision-making processes.
End of Discussion: A Guide To Understanding Recursion In Computer Science
So, you've journeyed through the world of recursion, from its fundamental concepts to its real-world applications. You've learned to identify base cases, navigate recursive steps, and appreciate both the elegance and potential pitfalls of this powerful programming paradigm. Remember, mastering recursion isn't just about understanding the mechanics; it's about developing the problem-solving skills to recognize when it's the perfect tool for the job. Now go forth and conquer those complex coding challenges!


{kind=link}